自从新型冠状病毒肺炎(COVID-19)爆发以来,这种疾病迅速在世界各国蔓延,在多个方面对全世界造成了严重的影响,如何更好地控制疫情成了世界各国政府必须共同面对的问题。疾病诊断是控制疾病传播的重要一步,因此如何更高效准确地诊断新冠肺炎成为一个值得研究的方向。核酸检测要求被检测者必须到医院、操场等特定地点进行检测,而且检测经济成本相对较高,也比较耗时。而利用声音信号来检测新冠肺炎可以进行远程操作,避免了检测过程中交叉传染,且检测时间更短,具有重要的研究意义和应用价值。
由ICASSP2022发起的第二届DiCOVA新冠声音信号检测挑战赛要求选手利用被检测人的呼吸、咳嗽、语音信号判断是否为新冠肺炎阳性,比赛包括呼吸、咳嗽、语音及融合任务四个赛道,采用AUC为分类评价指标,共吸引全球21支队伍参赛。最终中国科学技术大学团队提交的系统(NELSLIP-USTC,T-15)获得呼吸赛道亚军、语音赛道冠军、融合赛道冠军。相关系统描述论文“Supervised and self-supervised pretraining based COVID-19 detectionusing acoustic breathing/cough/speech signals”被ICASSP2022同时接收。在这项比赛中,语音及语言信息处理国家工程研究中心团队提出了基于有监督和自监督预训练的COVID-19检测方法,分类器基于双向长短时记忆网络。有监督预训练阶段通过不同的声学信号分别训练网络,为呼吸、咳嗽、语音三个任务建立单独的模型,将其模型参数权重平均得到一个平均模型,然后将其为每个任务的模型做初始化。这种初始化方法可以显著提高三个任务的性能,超过了官方的基线结果。在自监督预训练阶段,我们利用公开预训练模型wav2vec2.0模型并使用官方DiCOVA数据集对其进行预训练。该wav2vec2.0模型用于提取音频的高维表征作为模型输入,以代替传统的梅尔频率倒谱特征。实验结果表明,将高维特征和梅尔频率倒谱特征结合使用可以提高性能。为了进一步提高模型性能,我们还采用了一些预处理技术,比如切除无声片段,幅度归一化和频谱增强。提出的模型在DiCOVA数据集上进行评估,结果表明我们的方法在呼吸、咳嗽、语音和融合赛道的盲测数据集上的AUC分别达到了86.72、76.36、85.21、88.44。现对该论文进行简要的解读和分享。

图1 第二届DiCOVA挑战赛参赛队伍分布及成绩排名
论文题目:SUPERVISED AND SELF-SUPERVISED PRETRAINING BASED COVID-19 DETECTIONUSING ACOUSTIC BREATHING/COUGH/SPEECH SIGNALS
作者列表: 陈星宇、朱秋实、张结、戴礼荣
论文原文:https://ieeexplore.ieee.org/document/9746205

图2 发表论文截图

图3 扫码直接看论文
1.模型结构
整个新冠声音诊断系统的结构如图7所示,由预处理模块、编码器模块和分类器模块三部分组成。在编码器模块,两个双向LSTM层(BiLSTM)被用作编码器。每BiLSTM包括128个隐藏单元,dropout率设为0.1。两层全连接的前馈层被用作分类器模块,使用两个ReLU激活函数用于线性变换。由于新冠声音诊断是一个二分类问题,训练中使用二分类损失函数。
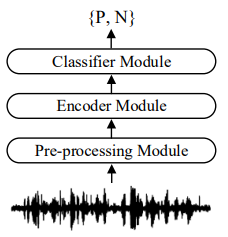
图4新冠肺炎声音检测系统结构
2.有监督预训练
在有监督预训练过程中,除了目标数据集之外,不使用任何额外的数据,训练过程如图8所示。假设需要训练一个诊断咳嗽声的模型,需要三个步骤:第一步:同时使用呼吸、咳嗽、语音三种声音数据,共同训练一个神经网络,该神经网络不用于分类,训练好后,内部参数被保存。第二步,搭建一个神经网络,然后用第一步保存的模型参数初始化这个神经网络。第三步,用第二步中被预训练模型初始化的神经网络在咳嗽数据上训练。呼吸、咳嗽、语音三种特定任务分别按上述训练过程训练,可以分别得到诊断三种声音的模型。上述有监督预训练方法由于使用了平均模型进行初始化,充分利用了数量有限的声音数据,编码器和分类器更容易获得最佳性能。

图5 有监督预训练过程
3.自监督预训练

图6 wav2vec2.0模型结构
虽然有监督预训练方法能部分解决数据过少的问题,但总的来看数据量还是相当有限,另外单一的 MFCC 特征也存在着信息量不足的问题,有必要使用其他的预训练方法。自监督属于无监督预训练的一种,基本思想是模仿有监督方法构造伪标签。wav2vec2.0 是一种常用的自监督模型,通常用于语音特征的提取,模型结构如图9所示。模型由卷积神经网络和 transformer 构成,可以分为特征编码器模块、上下文编码器模块和量化模块三部分。特征编码器模块由卷积神经网络构成,把原始音频信号波形转化为隐层语音表征;量化模块把隐层语音表征转化为量化表征,作为对比目标;上下文编码器模块把隐层语音表征转化为上下文表征。上下文表征和量化表征通过对比任务实现自监督预训练。训练好的 wav2vec2.0 模型可以看作一个特征提取器,声音信号通过 wav2vec2.0 模型输出一个表征向量,该表征向量可以代替传统的 MFCC、频谱等声学特征,也可以采用特征融合的方式与传统声学特征一起使用,以充分利用不同特征间的互补性。由于 wav2vec 的训练过程利用了大量的数据,网络得以充分学习大数据中的信息。本章采用的自监督预训练过程如下:wav2vec2.0 模型首先在公开的大数据集上进行无标签的训练,公开数据集上训练好的模型在新冠声音数据集再次进行无标签训练,最后得到的wav2vec2.0 模型作为特征提取器,用提取到的高阶特征替代 MFCC 特征输入诊断模型进行分类。
4.模型集成与模型融合
本文采用的有监督预训练过程中,模型采用MFCC特征作为输入。而在自监督预训练过程中,诊断模型的输入是用wav2vec2.0模块提取的高阶特征。高阶特征与MFCC包含的信息有区别,本课题使用模型集成的方法,充分利用不同特征的互补性。对于一种特定的声音类型(如咳嗽声),通过自监督预训练和有监督预训练两种方法可以分别得到两个分数。
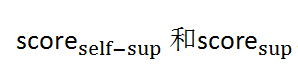
把两个分数进行集成可得
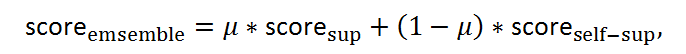
其中权重系数可以根据需求选择。
在融合任务中,需要结合三种不同的声音类型(呼吸、咳嗽、说话声)综合判断,由于三种模型各自输出一个分数,可以使用加权求和的方法得到融合模型的分数:
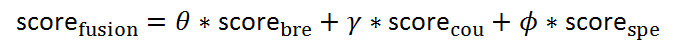
这里参数需要满足,参数的选择需要考虑呼吸、咳嗽、说话声对新冠肺炎检测的重要性,也应当考虑信号的质量。
5.实验验证
Coswara数据集是新冠声音检测任务最常用的数据集之一,声音数据通过web应用采集自世界各地的志愿者,其中既有新冠检测阳性的患者,也有新冠检测阴性的健康人,志愿者们被要求在安静环境下通过手机等移动设备录制他们的呼吸声、说话声、咳嗽声三种声音并上传。原始Coswara数据集未经筛选过,存在许多质量低的数据,如不含任何声音的数据或存在噪声的数据,且标签由志愿者自行提供,不一定可靠。本章使用的数据集来自DiCOVA-ICASSP 2022 新冠声音检测挑战赛,该挑战赛数据集是Coswara数据集的子集,所有数据经ICASSP 2022主办方筛选过,确保信号和标签可靠,且所有声音数据均不含噪声。所有声音信号的采样率为44.1kHz,文件为FLAC格式。声音数据的时长从1秒到29秒不等。每位志愿者的声音包括呼吸、咳嗽和语音三类,每类各一条。咳嗽声来源于志愿者的主动咳嗽。语音内容是用英语读1至20的数字。训练集共包含965位志愿者的声音数据,包括793位新冠阴性志愿者和172位新冠阳性志愿者。测试集包含471位志愿者的声音数据,其中阳性60位,阴性411位。训练集与测试集无重复数据。图7是三类声音的语谱图示例,左列为阴性样本,右列为阳性样本。由语谱图可以发现阳性样本能量集中于低频,阴性样本能量是全频带的,尤其对于咳嗽和语音而言,这些特点使得从声音中检测新冠肺炎有了理论依据。
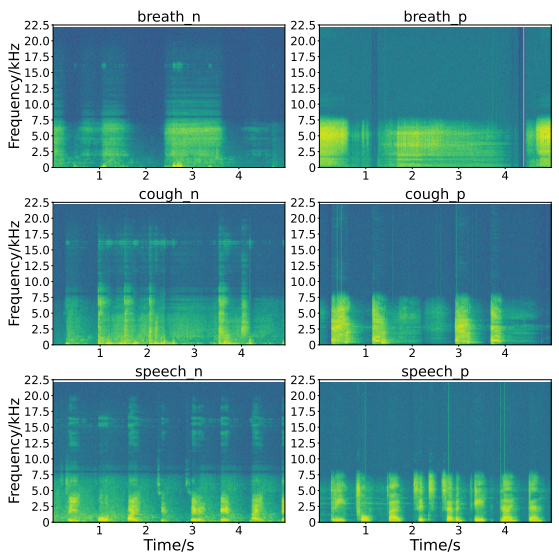
图7 呼吸、咳嗽、语音三类信号的语谱图
在预处理阶段,原始波形数据被归一化到-1至1之间。由于原始声音信号存在静音段,使用语音活动检测器(VAD)去除。声音数据被降采样至16kHz,按帧长25ms、帧移10ms分帧,然后提取13维MFCC及其一阶、二阶差分,再加上1维能量,拼接得到40维的特征。由于训练数据规模较小,本课题使用SpecAugment时频掩模用于数据增强,时域掩模长度为20,频域掩模长度为50。分类器模型包括两层BiLSTM和两层全连接层。两层BiLSTM层的维度为128,每层LSTM后设一个dropout层,dropout比率设为0.1。BiLSTM的输出经过平均池化后输入前馈神经网络。两层全连接层的激励函数使用ReLU函数,每层节点数为256。损失函数采用二分类交叉熵。在有监督预训练阶段,用呼吸、咳嗽、语音三种声音训练同一个BiLSTM网络,用2张RTX3090ti-24GGPU训练50轮。在自监督预训练阶段,使用fairseq工具箱实现wav2vec2.0模型。wav2vec2.0的特征编码器包括7个卷积块,每个卷积块包括512个时域卷积通道,卷积步长分别为(5,2,2,2,2,2,2),卷积核大小分别为(10,3,3,3,3,3,2,2)。上下文编码器模型包括12个维数为512的transformer编码器块和一个2048维的前馈神经网络。预训练过程使用Adam优化器。模型首先在960小时的Librispeech数据集上进行自监督预训练。Librispeech数据集是无标签的语音数据集,包含960小时的英语语音信号。Librispeech数据集上训练好的wav2vec2.0在DiCOVA-ICASSP2022数据集的对应任务上再次进行无标签训练。两次无标签训练后,wav2vec2.0模型参数被冻结,预训练好的模型被用作高阶特征提取器,用于从原始波形中提取高阶特征,用高阶特征代替MFCC特征输入分类器模型。为了对比,本课题也测试了CNN、LSTM以及DiCOVA-ICASSP2022挑战赛官方基线系统的性能。实验结果如表1所示,实验结果表明,本章提出的两种预训练方法相比CNN、LSTM和官方基线方法能获得更高的ROC-AUC值,因为预训练模型可以为分类器提供更多的信息,在数据集小的情况下效果尤其明显。有监督预训练方法在呼吸、咳嗽、语音三类任务上的ROC-AUC值分别达到86.41/76.05/85.02,相比于基线系统的84.50/74.89/84.26提升很大。自监督预训练模型在三种任务上的AUC分别达到86.22/75.55/84.35,虽然提升幅度相对于有监督预训练小,但性能依然优于基线系统。将自监督预训练与有监督预训练结合起来,可以进一步提升检测性能,实验结果显示,模型集成的方法在呼吸、咳嗽、语音三类任务上的AUC分别达到86.72/76.36/85.21,比单独使用一种特征的效果更好,可见wav2vec2.0模型提取的高阶特征与低阶MFCC特征具有互补性。在融合任务上,总的输出概率由三种任务的输出概率按照一定的权重相加得到,如表2所示,当呼吸、咳嗽、语音三类任务的权重设置为0.4/0.2/0.4时,检测效果最好,ROC-AUC得分达到88.44。
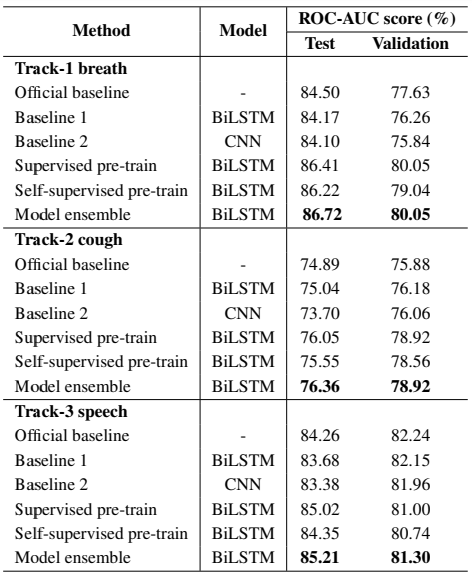
表1 呼吸/咳嗽/语音赛道下的AUC结果
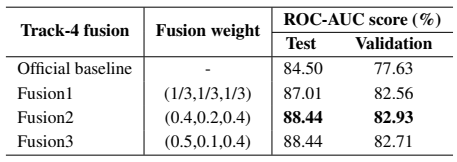
表2 融合赛道下的AUC结果
