

近日,Interspeech 2023会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共14篇论文被会议接收,论文方向涵盖语音识别、语音合成、话者识别、语音增强、情感识别、声音事件检测等,各接收论文简介见后文。
Interspeech是由国际语音通信协会(ISCA)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会。本届会议以“Inclusive Spoken Language Science and Technology – Breaking Down Barriers”为主题,内容涵盖语音识别、语音合成、语音增强、自然语言处理等多个领域。
语音及语言信息处理国家工程实验室于2011年由国家发展改革委正式批准成立,由中国科学技术大学和科大讯飞股份有限公司联合共建,是我国语音产业界唯一的国家级研究开发平台。2021年底,实验室通过国家发展改革委的优化整合评估,成功纳入新序列,并转建为语音及语言信息处理国家工程研究中心。
1. Incorporating Ultrasound Tongue Images for Audio-Visual Speech Enhancement through Knowledge Distillation
论文作者:郑瑞晨,艾杨,凌震华
论文单位:中国科学技术大学
论文简介:
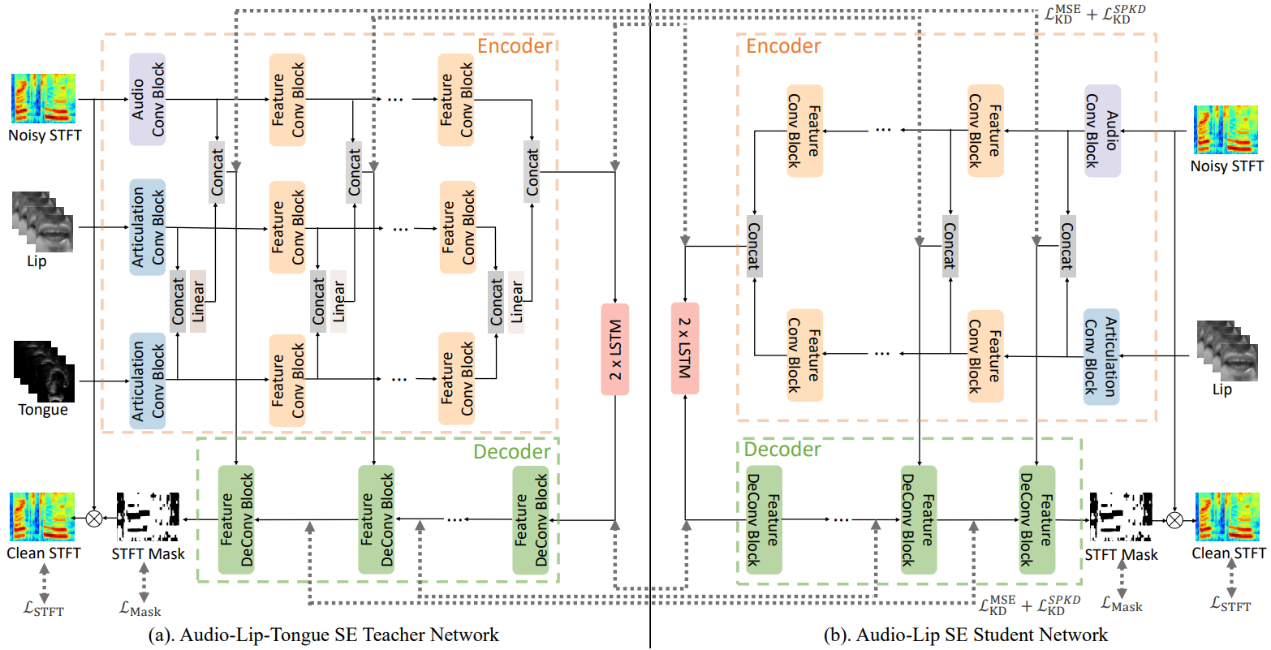
音视频语音增强(Audio-Visual Speech Enhancement, AV-SE)旨在结合额外的视觉信息(如唇部视频)对被噪声干扰的语音进行降噪。已有研究证明,与仅利用音频进行语音增强相比,音视频语音增强更加有效。本文提出进一步引入超声舌头图像以改善基于唇部视频的AV-SE系统的性能。然而与唇部视频相比,超声舌头图像的获取成本通常较高,在实际应用时通常难以获得。为了解决这一问题,我们提出可以在训练阶段采用知识蒸馏的方法,使音频-唇部语音增强的学生模型能够从一个预训练好的音频-唇部-舌头语音增强的教师模型中学习舌部知识。在推断时只需输入带噪语音和对应的唇部视频,无需输入超声舌头图像,也可以利用模型已学习到的舌部知识辅助语音增强。实验结果表明,与传统的音频-唇部语音增强相比,所提出的方法显著改善了语音的质量和可懂度。进一步使用自动语音识别引擎分析降噪后语音的音素错误率显示,与舌头相关的音素(如腭音和软腭音)从引入超声舌头图像中受益最大。
论文资源:论文预印版下载地址https://arxiv.org/abs/2305.14933(或扫描下方二维码)

Demo语音网页 https://zhengrachel.github.io/UTIforAVSE-demo/(或扫描下方二维码)

2. MP-SENet: A Speech Enhancement Model with Parallel Denoising of Magnitude and Phase Spectra
论文作者:鲁叶欣,艾杨,凌震华
论文单位:中国科学技术大学
论文简介:

本文提出了一种基于幅度相位谱平行去噪的单通道语音增强方法。该方法提出的语音增强模型整体为编码-解码器结构,编码器将输入的带噪幅度谱和相位谱编码成时频域表征,而平行的幅度掩膜解码器和相位解码器分别从时频域表征中解码出干净的幅度谱和相位谱,再重构短时谱后通过逆短时傅里叶变换得到干净的语音波形。提出的方法设计了针对相位谱预测的平行估计架构并且使用抗卷绕损失对增强的相位谱进行优化,是首个实现对相位谱直接去噪的语音增强方法,相比于之前的语音增强方法成功缓解了幅度谱和相位谱之间的补偿效应并实现了更好的谐波恢复效果。实验结果表明,在通用的 VoiceBank+DEMAND 数据集上,我们的模型取得了 3.50 的 PESQ 得分,优于现阶段其他的语音增强方法。
论文资源:论文预印版下载地址https://arxiv.org/abs/2305.13686
Demo语音网页 https://github.com/yxlu-0102/MP-SENet
3. BASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
论文作者:张结,徐擎天,朱秋实,凌震华
论文单位:中国科学技术大学,四川大学
论文简介:

时域语音增强在多说话人场景下仍然是具有挑战性的任务,尤其在没有额外关于目标说话人信息的情况下。随着脑科学领域的不断发展,研究表明能够从听者的脑电EEG信号中重建出所听到的语音信息,证明了脑电信号与目标说话人语音信号之间的关联性。本文提出了一种新的时域基于 EEG 信号的语音增强模型(BASEN: Brain-Assisted Speech Enhancement Network),来解决多说话人场景的语音增强问题。其中,我们提出了Convolutional Multi-Layer Cross Attention (CMCA)方法对语音特征和 EEG 特征进行融合。在公开数据集上的对比实验表明了所提出的BASEN方法相对于当前领域内最优U-BESD方法的优越性。
论文资源:论文预印版下载地址https://arxiv.org/abs/2305.09994
开源代码下载地址 https://github.com/jzhangU/Basen
4. Variance-Preserving-Based Interpolation Diffusion Models for Speech Enhancement
论文作者:郭子路,杜俊,李锦辉,高羽,张文彬
论文单位:中国科学技术大学,佐治亚理工学院,美的上海AI创新中心
论文简介:
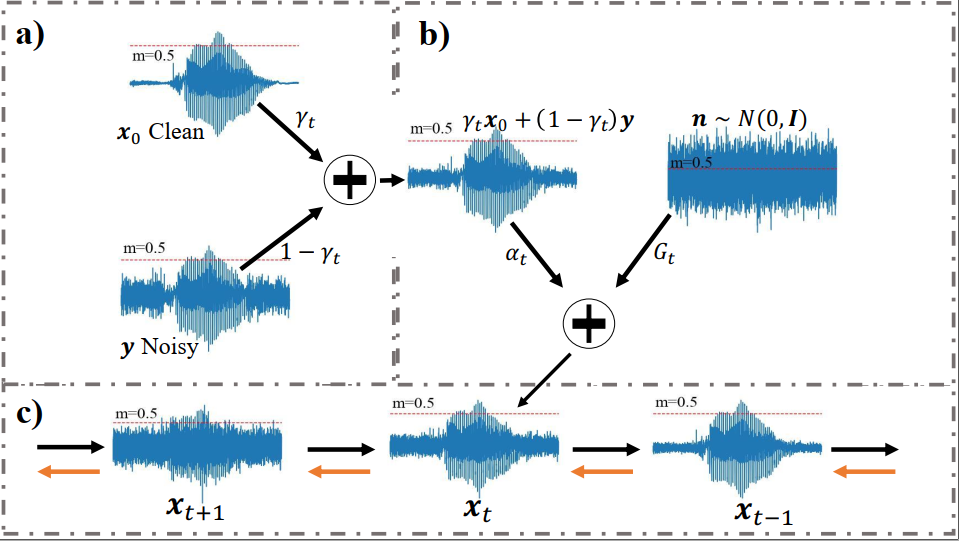
本文的目的是分析语音增强任务中扩散模型的理论。首先我们给出连续条件下的方差保存—VP(Variance Preserving)的插值扩散模型的数学模型。然后提出一个更简洁的模型用以概述VP和VE(Variance Exploding)两种插值扩散模型。接着给出证明VP和VE插值模型是该统一模型的两种特例。随后,我们设计了一个VP插值扩散模型用于语音增强任务。针对扩散模型迁移到语音增强任务训练困难问题,我们分析了难收敛的原因,给出了如何设计超参的一种思路。最后我们在公开数据集上评估了所提算法的出色的性能。
5. Speech Synthesis with Self-Supervisedly Learnt Prosodic Representations
论文作者:刘朝辞,凌震华,胡亚军,潘嘉,伍芸荻,王瑾薇
论文单位:中国科学技术大学,科大讯飞
论文简介:
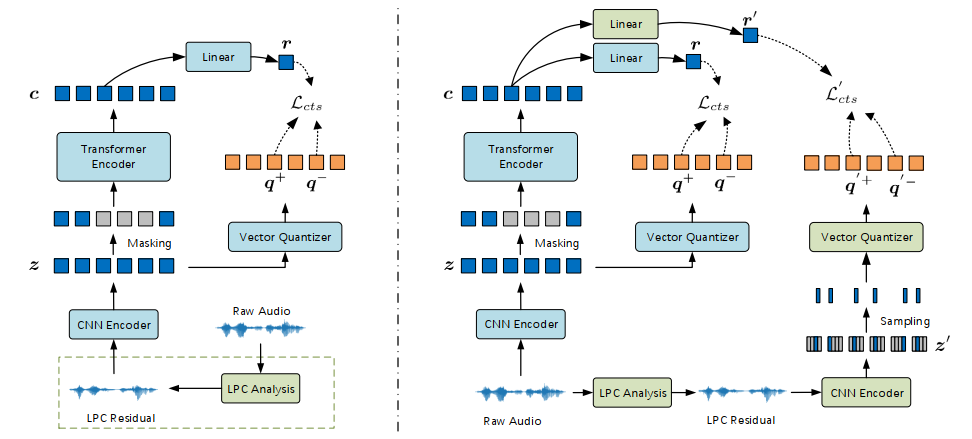
我们提出了一种基于自监督学习的韵律表示的语音合成模型S4LPR (Speech Synthesis with Self-Supervisedly Learnt Prosodic Representations)。该模型不使用原始声学特征(如F0和能量)作为表示韵律的中间变量,而是设计并比较了三种提取帧级韵律表示的自监督语音模型,自监督模型在大规模无标签数据上预训练,之后用于提取语音合成任务的韵律表征。除了原始wav2vec 2.0模型,本文还采用了另外两种预训练模型,它们从LPC残差中学习韵律表征。同时,为了更好地关注语音中的韵律信息,本文采用了多任务学习策略。我们的语音合成声学模型基于FastSpeech2和PnGBERT,构建在所学习的韵律表示之上。实验结果表明,使用S4LPR合成的语音自然度明显优于FastSpeech2基线。
论文资源:Demo语音网页 https://ttsbylzc.github.io/ttsdemo202303/(或扫描下方二维码)

6. CASA-ASR: Context-Aware Speaker-Attributed ASR
论文作者:史莫晗,杜志浩,陈谦,俞帆,李泱泽,张仕良,张结,戴礼荣
论文单位:中国科学技术大学,阿里巴巴达摩院
论文简介:
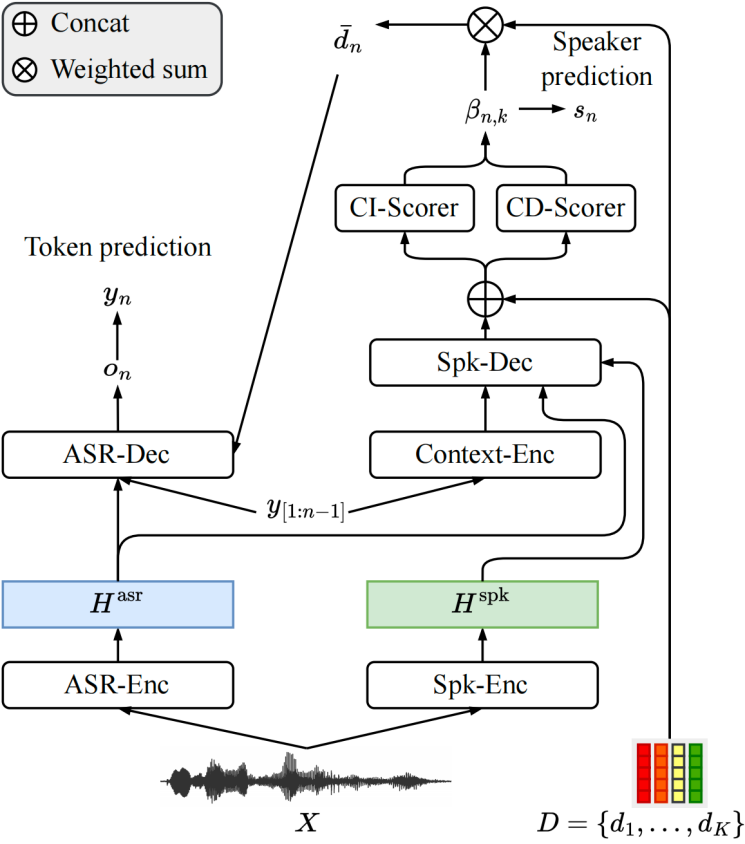
说话人相关语音识别(Speaker Attributed Automatic Speech Recognition, SA-ASR)的目标是解决多说话人场景下“谁说了什么”的问题。原有的端到端(End to End, E2E)SA-ASR方法由于缺乏对上下文信息的感知而表现不佳,因此本文基于E2E SA-ASR提出了一种带有上下文感知的SA-ASR(Context-Aware Speaker-Attributed ASR, CASA-ASR)方法。具体而言,在CASA-ASR中,使用上下文文本编码器来整合整个语句的语义信息,并使用上下文相关打分器,通过与上下文的说话人进行对比来对说话人的可辨别性进行建模。此外,为了充分利用上下文建模能力,进一步提出了两阶段解码策略,从而获得更好的识别性能。在AliMeeting语料库上的实验结果表明,所提出的方法在说话人相关字错误率(Speaker Dependent Character Error Rate, SD-CER)指标优于E2E SA-ASR方法,达到了最佳性能。
论文资源:论文预印版下载地址https://arxiv.org/abs/2305.12459
7. Real-Time Causal Spectro-Temporal Voice Activity Detection Based on Convolutional Encoding and Residual Decoding
论文作者:王景渊,张结,戴礼荣
论文单位:中国科学技术大学
论文简介:

语音活动检测(voice activity detection, VAD)是许多语音应用中的关键前端,旨在确定音频帧中是否存在语音信号。然而,传统的VAD方法在低信噪比环境下往往表现出性能不佳或非因果关系。因此,在这项工作中,我们提出了一种实时因果VAD模型,主要包括频域特征生成模块、基于卷积的编码模块和基于残差块的解码模块。仅利用当前和过去的帧进行特征提取确保了因果性。在各种噪声条件下,我们验证了所提出模型的有效性。结果显示,所提出的方法可以达到与最先进的非因果模型相当甚至更好的性能。
8. Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
论文作者:史莫晗,舒钰淳,左玲云,陈谦,张仕良,张结,戴礼荣
论文单位:中国科学技术大学,天津大学,阿里巴巴达摩院
论文简介:
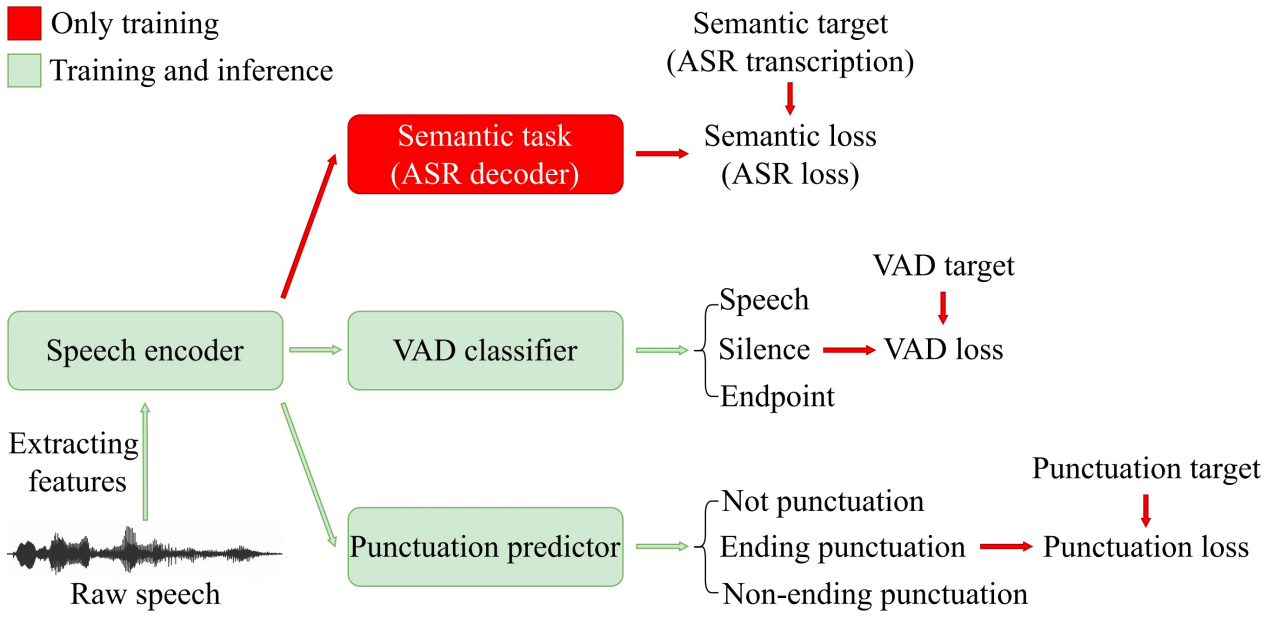
在语音交互场景下,语音活动检测(Voice Activity Detection, VAD)常被用作前端来对长音频进行切分。然而,传统的VAD算法通常需要等待的尾部静音达到预设的阈值时间后才进行分割,导致延迟较高,影响用户体验。因此,本文提出了一种语义VAD方法进行低延迟切分。与现有方法不同的是,在语义VAD中增加了帧级标点符号预测任务;另外,除了常用的语音和非语音二分类之外,还将人工设定的尾部端点纳入VAD分类的类别中;为了增强模型的语义建模能力,我们在还在损失函数中加入了语音识别(Automatic Speech Recognition, ASR)损失进行辅助训练。在内部数据集上的实验结果表明,与传统的VAD方法相比,该方法降低了53.3%的平均延迟,而对于下游的语音识别任务并没有显著的性能退化。
论文资源:论文预印版下载地址https://arxiv.org/abs/2305.12450
9. Unsupervised Adaptation with Quality-Aware Masking to Improve Target-Speaker Voice Activity Detection for Speaker Diarization
论文作者:牛树同,杜俊,何茂奎,李锦辉,李宝祥,李家魁
论文单位:中国科学技术大学,佐治亚理工学院,商汤科技
论文简介:
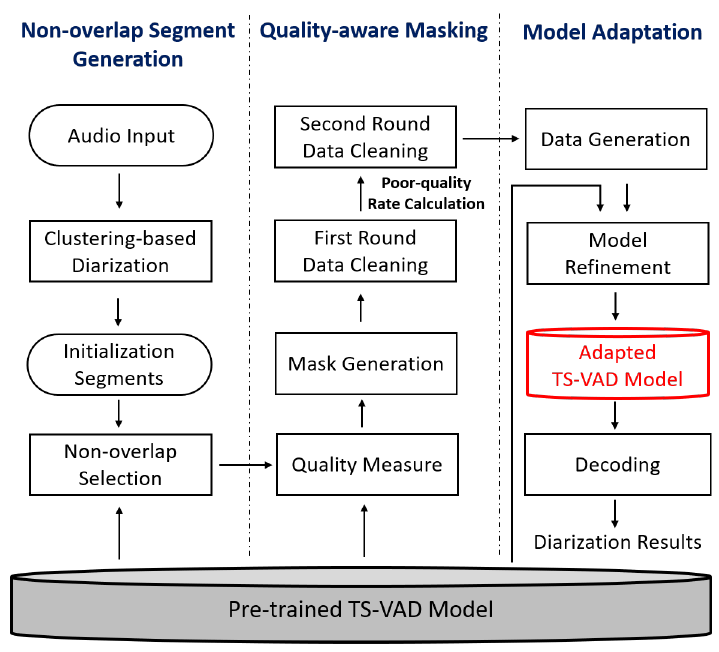
在本文中,我们提出了一种基于质量相关动态掩膜的目标说话人语音活动检测方法(quality-aware masking TS-VAD,QM-TS-VAD)。该方法可以在目标说话人语音活动检测(TS-VAD)进行无监督自适应的过程中减少伪标签的错误所带来的负面影响。此外,通过知识蒸馏的方法,QM-TS-VAD还可以作为教师模型来优化学生模型,从而进一步减小过拟合的问题。我们在DIHARD-III挑战赛的八个场景中对所提出的方法进行了测试。实验结果表明,我们提出的QM-TS-VAD方法可以有效地提高说话人日志系统的性能,引入知识蒸馏的方法可以使得模型性能在其中的七个场景中得到进一步的提升。此外,我们提出的自适应方法相比于DIHARD-III挑战赛冠军的自适应方法取得了更好的性能。
10. Fine-tuning Audio Spectrogram Transformer with Task-aware Adapters for Sound Event Detection
论文作者:李康,宋彦,Ian McLoughlin,柳林,李晋,戴礼荣
论文单位:中国科学技术大学,新加坡理工大学,科大讯飞
论文简介:
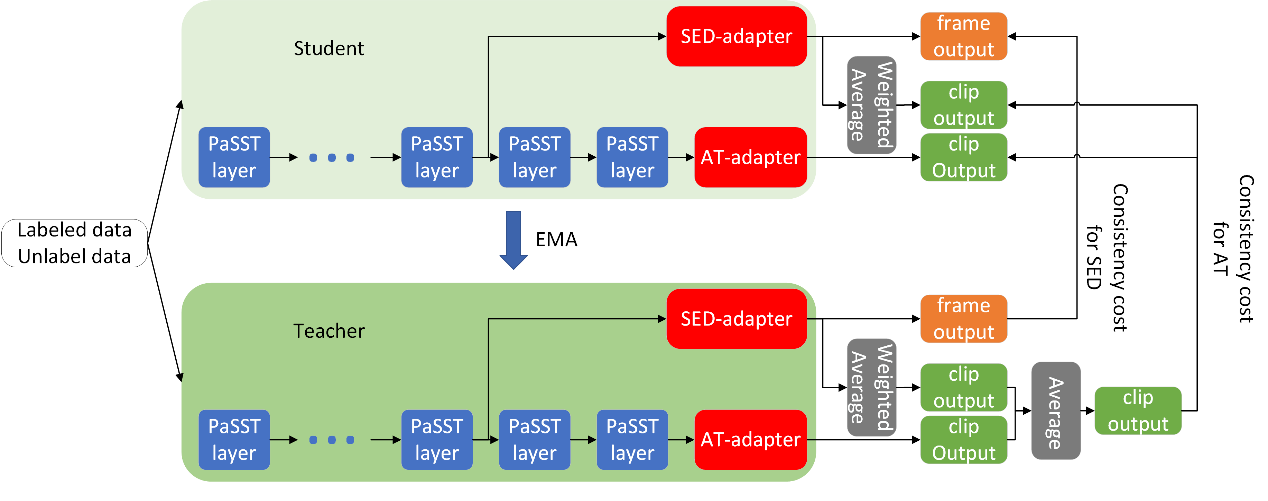
大规模数据预训练的PaSST模型在音频分类(AT)任务上取得了优异的表现,如何将PaSST迁移到声音事件检测(SED)任务上有待研究。 本文提出了一种任务感知微调(task-aware fine-tuning)策略,来充分利用PaSST模型的知识。具体而言,本文引入了两种任务适配器,SED适配器和AT适配器,前者利用PaSST的浅层局部信息解码出高时间分辨率特征,并进一步得到帧级预测,经过linear-softmax池化后,得到段级预测;后者利用PaSST深层的语义信息直接产生段级预测。 在平均教师(mean teacher)半监督方法的框架下,教师模型集成两个适配器的段级预测,产生更精确的段级伪标签,并指导学生模型中两个适配器学习,从而提高模型的事件检测性能。 此外,我们还提出自蒸馏平均教师(self-distillated mean teacher)半监督方法,减少噪声标签对训练的影响。 我们的系统取得了在DCASE 2022 task4 开发集上目前已知的最优结果。
11. Robust Prototype Learning for Anomalous Sound Detection
论文作者:曾晓敏,宋彦,Ian McLoughlin,柳林,戴礼荣
论文单位:中国科学技术大学,新加坡理工大学,科大讯飞
论文简介:
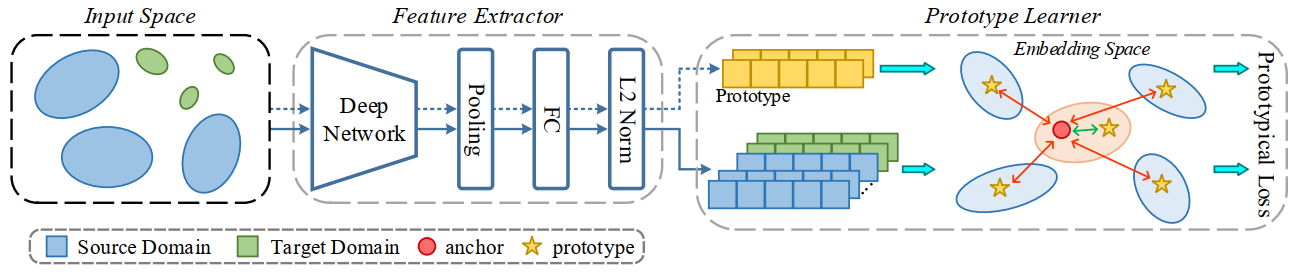
本文提出了一种用于异常声学检测的鲁棒性原型学习框架,其中利用了原型损失来度量样本和原型之间的相似性。从原型学习的角度,异常声学检测中的生成式方法和区分式方法能够被统一到该框架中。针对最近DCASE挑战中的异常声学检测任务,我们提出了关于不平衡学习的多种扩展并应用到该框架中,以提高源域和目标域原型的鲁棒性。具体地,我们提出平衡采样和多原型扩展(Multi-Prototype Expansion,MPE)来解决源域和目标域之间属性的不平衡问题。此外,为了学习更紧凑和有效的正常样本特征空间,负原型扩展(Negative Prototype Expansion,NPE)被应用于构建异常样本的表示。在DCASE2022 Task2开发集上的实验结果证明了原型学习框架的有效性。
12. Introducing Self-Supervised Phonetic Information for Text-Independent Speaker Verification
论文作者:张子扬,郭武,古斌
论文单位:中国科学技术大学
论文简介:
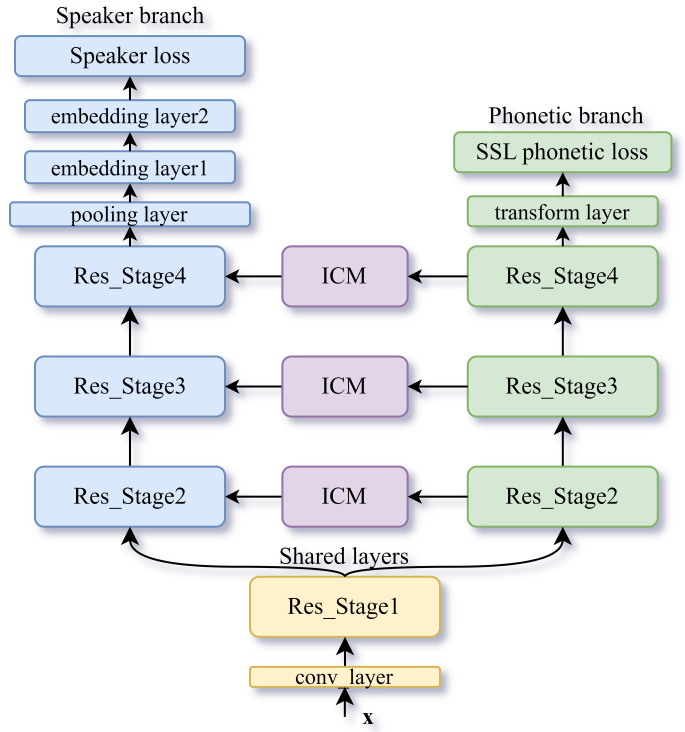
本文提出了一种新颖的多任务学习框架,将自监督的语音信息引入深度说话人嵌入提取中。具体而言,主任务仍是对说话人进行分类,辅助任务是利用噪声对比估计原理识别语音信号中的音素边界。为了进一步利用自监督信息来辅助说话人特征学习,辅助任务中中间层的特征通过掩蔽和偏置操作细化了主任务中相应层的特征。实验在VoxCeleb1 和 CN-Celeb 数据集上进行,结果表明,所提出的方法可以一致提升说话人验证系统的性能。
13. A Multiple-Teacher Pruning Based Self-Distillation (MT-PSD) Approach to Model Compression for Audio-Visual Wake Word Spotting
论文作者:王皓天,杜俊,周恒顺,李锦辉,赵江江,任玉玲
论文单位:中国科学技术大学,佐治亚理工学院,中移在线服务有限公司
论文简介:
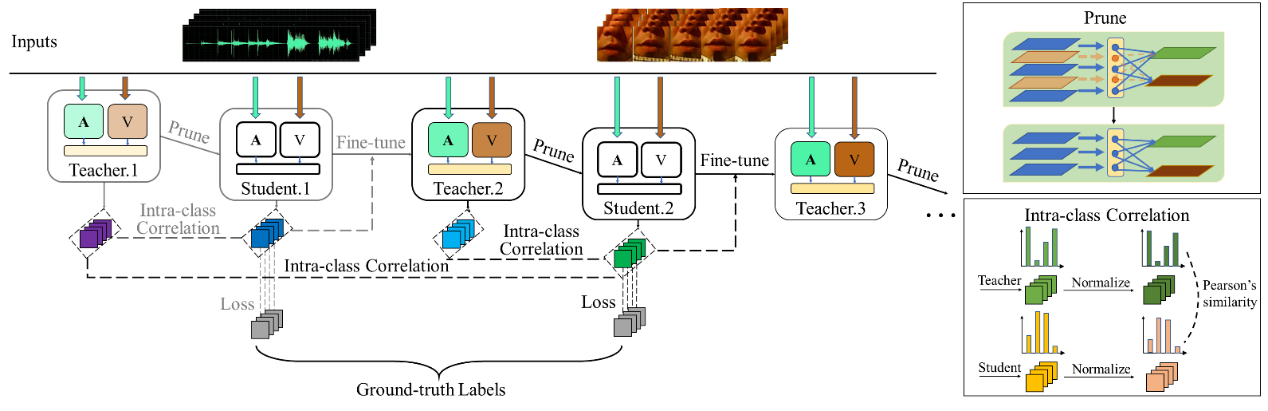
引入视频信息的音视频唤醒词识别(Audio-Visual Wake Word Spotting, AVWWS)相对单音频效果更优,系统鲁棒性更强,但是处理视频信息的视频支路会引入大量的额外参数量,不利于音视频唤醒网络的实际落地。在本文中我们提出了一种新颖的模型压缩方法,使用基于多教师剪枝的自蒸馏框架构建了音视频唤醒词识别网络,在不牺牲系统性能的情况下实现了紧凑的神经网络结构设计。在所提出的框架中的每个阶段,我们对前一阶段获得的教师模型进行剪枝生成学生模型,然后根据师生学习的原则对其进行微调,并将其用作下一阶段的新教师模型。我们设计了一个归一化的类内损失来优化这种基于剪枝的自蒸馏(Pruning Based Self-Distillation, PSD)过程。每个阶段的微调过程我们都分别采用了单教师指导PSD(ST-PSD)和多教师指导PSD(MT-PSD)两种模式。当在MISP2021挑战赛的音视频唤醒词识别基线网络上进行测试时,所提出的两种技术在系统性能和模型复杂度方面都优于最先进的方法。此外,利用不同阶段获得的多个教师的互补性的MT-PSD效果也优于ST-PSD。
14. AD-TUNING: An Adaptive CHILD-TUNING Approach to Efficient Hyperparameter Optimization of Child Networks for Speech Processing Tasks in the SUPERB Benchmark
论文作者:杨高斌, 杜俊,何茂奎,牛树同,李宝祥,李家魁,李锦辉
论文单位:中国科学技术大学, 佐治亚理工学院, 商汤科技
论文简介:
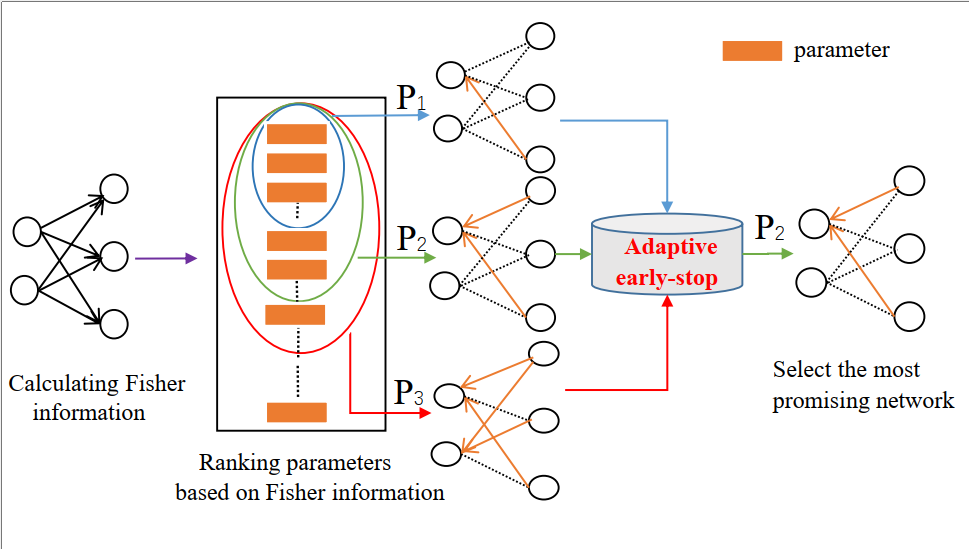
本文提出了AD-TUNING,一种用于子网络超参数调整的自适应CHILD-TUNING方法。为了解决选择最佳超参数集P的问题,我们首先分析了参数重要性的分布,以确定P的范围。 接下来,我们提出了一个简单而有效的早期停止算法,为各种语音任务从不同的规模中选择合适的子网络。在对SUPERB基准中的七项语音处理任务进行评估时,我们提出的框架只需要对每个任务的预训练模型参数进行小于0.1%∼10%的微调,就能在大多数任务中取得最先进的结果。
论文资源:开源代码下载地址https://github.com/liyunlongaaa/AD-TUNING