

近日,ICASSP 2024会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共18篇论文被会议接收,论文方向涵盖语音识别、语音合成、话者识别、语音增强、情感识别、声音事件检测等,各接收论文简介见后文。此次会议的Grand Challenge论文接收结果预计1月发布,暂未包括。
ICASSP (International Conference on Acoustics, Speech, and Signal Processing)是IEEE信号处理学会(Signal Processing Society)的学术年会,是全世界规模最大、最全面的声学、语音和信号处理及其应用方面的国际会议,也是语音技术领域最具影响力的顶级国际会议。本届会议以“Signal Processing: The Foundation for True Intelligence”为主题,内容涵盖语音识别、语音合成、语音增强、自然语言处理、机器学习等多个领域。
1. Considering Temporal Connection Between Turns for Conversational Speech Synthesis
论文作者:梅康迪,刘朝辞,杜荟鹏,李恒宇,艾杨,陈丽萍,凌震华
论文单位:中国科学技术大学
论文简介:
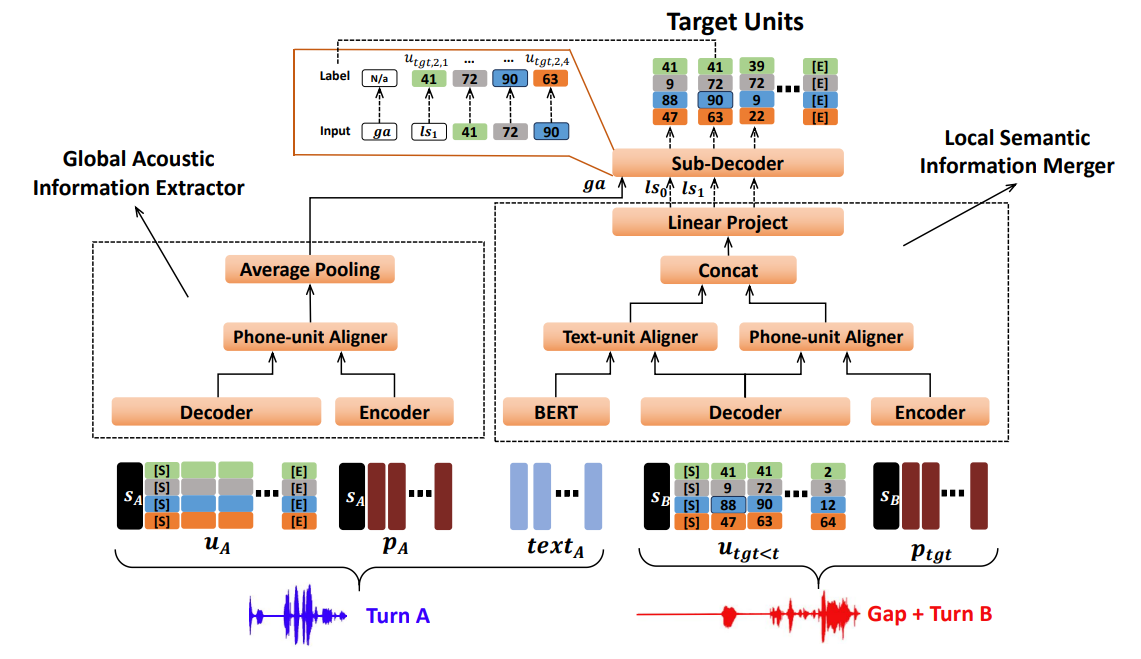
对话语音合成(conversational speech synthesis)旨在根据历史对话合成说话者的语音。然而,大多数有关对话语音合成的研究主要关注当前说话者的合成性能,而忽略了对话者轮次(turn)之间的时序关系。因此,我们考虑了对话语音合成中轮次之间的时序连接,这对于对话的自然性和连贯性至关重要。具体而言,本文提出了一项任务,其中各轮次间在时序上没有重叠,并且仅考虑一个历史轮次。为完成这项任务,我们提出了一个声学模型,该模型利用历史轮次的多模态(包括文本和语音)信息,来预测当前轮次以及轮次间的间隔(gap)的声学特征。我们的模型基于MQTTS设计,并在预测每一帧的声学特征时结合了历史轮次的全局声学表征和基于BERT的局部语义表征。实验结果表明,引入全局声学信息和局部语义信息后,我们的模型在轮次间的时序连接和当前轮次的内容合成上均取得了更好的性能。
论文资源:Demo语音网页https://mkd-mkd.github.io/icassp2024/
2. An Experimental Comparison of Noise-robust Text-to-Speech Synthesis Systems based on Self-Supervised Representation
论文作者:赵肖英,朱秋实,胡雨晨,张结
论文单位:中国科学技术大学,南洋理工大学
论文简介:
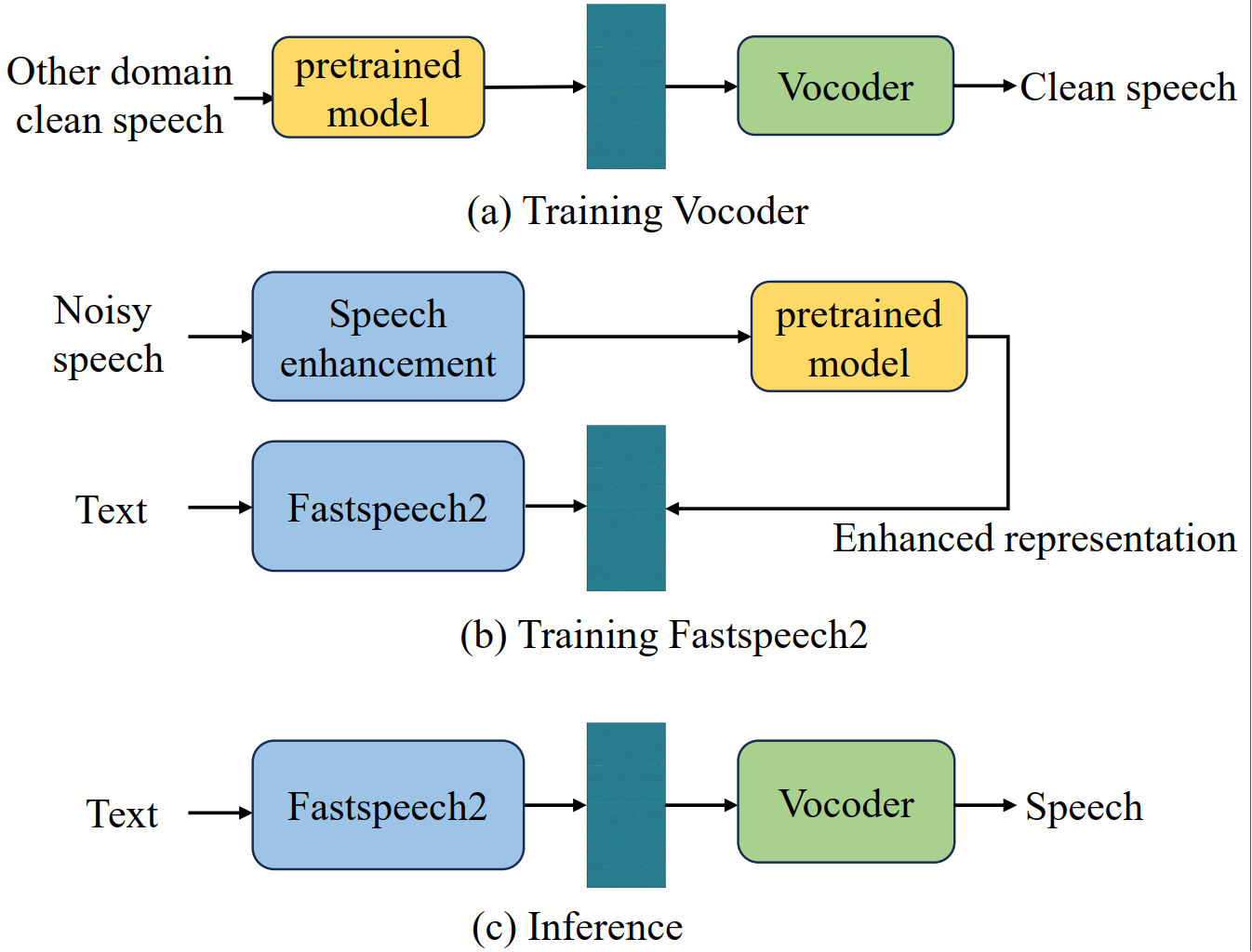
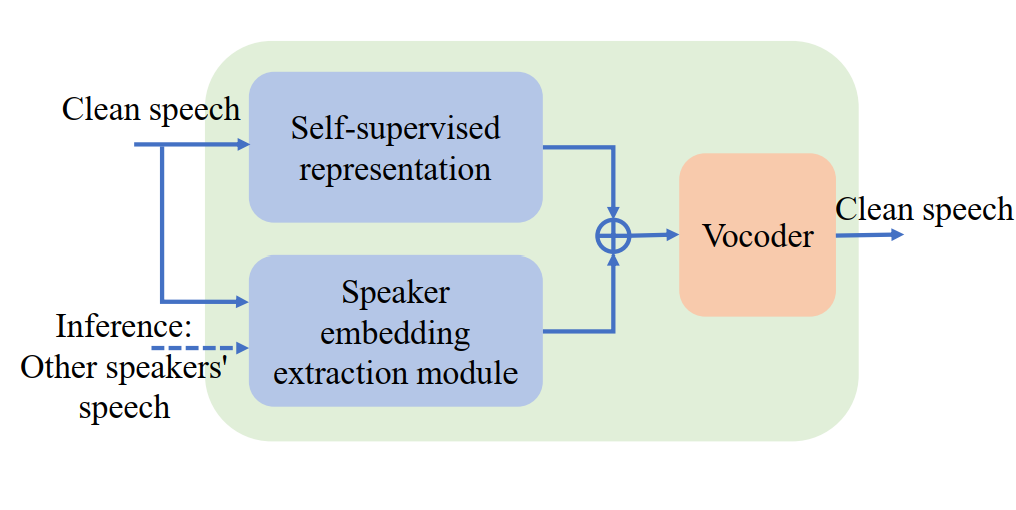
得益于深度学习的发展,使用干净语音的文本转语音 (TTS) 模型性能得到了显著提升。由于真实场景收集的数据常含有噪声,一般需要经过语音增强模型去噪,因此在增强语音上训练的TTS模型会出现失真和残留噪声,从而影响合成语音的质量。同时,自监督预训练模型在许多任务中表现出良好的噪声鲁棒性,这表明其学习到的表征对噪声扰动具有更强的容忍度。研究表明,基于 WavLM 表征的语音合成具有一定的抗噪能力,但不同的自监督表征对性能的影响仍然未知。因此,在本文中,我们使用一个基于 HiFi-GAN 的表征到波形的声码器和基于 Fastspeech的文本到表征的声学模型,我们通过实验比较了 TTS 的四种自监督表征(如WavLM、Wav2vec2.0、HuBERT、Data2vec)。由于这些表征具有更好的抑制噪声和说话人信息的能力,因此我们进一步集成说话人嵌入来进行语音转换。在LJSpeech和LibriTTS数据集上的实验结果表明方法的有效性。
3. Sifisinger: A High-Fidelity End-to-End Singing Voice Synthesizer Based on Source-Filter Model
论文作者:崔建伟,顾宇,翁超,张结,陈丽萍,戴礼荣
论文单位:中国科学技术大学,腾讯
论文简介:
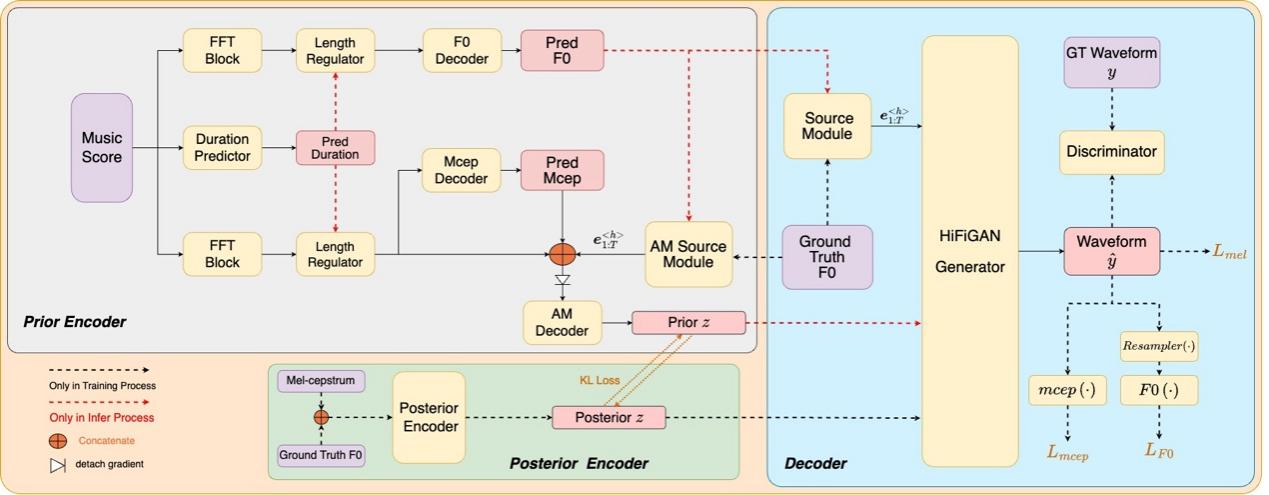
本文提出了一种基于Source-Filter理论的端到端歌声合成(SVS)系统,该系统直接将歌词和乐谱信息转化为具有表现力和高保真度的像人类一样的歌唱声音。与 VISinger 2 类似,本文提出的系统还利用从 VITS 演变而来的训练范式,并结合音高 (F0) 预测器和波形生成器等元素。 为了解决与F0信息具有耦合的梅尔谱特征可能会引入错误的问题,在预测F0时,我们考虑两种策略。首先,我们利用梅尔倒谱 (Mel-cepstrum) 特征来解耦交织的梅尔频谱和F0特征。 其次,受Neural Source-Filter模型的启发,我们将源激励信号引入为SVS系统中F0的表示,旨在捕捉更准确的音高细微差别。 同时,可微的梅尔倒谱和 F0损失函数作为波形解码器的更直接的监督项,以确保生成的语音中语音包络和音调的预测精度。 Opencpop 数据集上的实验证明所提出的模型在合成质量和音高音调方面的提升。
论文资源:Demo语音网页 https://sounddemos.github.io/sifisinger
4. Modeling Pseudo-Speaker Uncertainty in Voice Anonymization
论文作者:陈丽萍,Kong Aik Lee,郭武,凌震华
论文单位:中国科学技术大学,新加坡理工大学
论文简介:
本文描述了一项声音匿名化方向的工作。声音匿名化的研究目标在于保护原语音中的说话人信息不被恶意利用,在VoicePrivacy Challenge提出的声音匿名化框架中,采用利用说话人转换技术,将语音中的原说话人转换到伪说话人上,实现对原说话人的保护,其中,伪说话人由从一个预先给定的说话人库中,根据一定准则挑选出的一组背景说话人构造得到。本文的研究目标在于如何根据挑选出的背景说话人构造伪说话人,以加大由不同说话人组构造出的伪说话人之间的差异,提高每一个伪说话人的独特性。为此,本文提出基于xi-vector框架中对说话人信息的分布(均值,方差)的估计,通过最小化伪说话人分布与说话人组语音中的说话人分布的Kullback-Leibler散度,估计出伪说话人分布,用作声音转换中的说话人表征,实现匿名化。本文提出的方法在以匿名化语音作为注册和测试语音的说话人确认测试中,拿到了50%左右的等错误率(该等错误率越高,伪说话人的独特性越高),证明了本文提出的方法在匿名化任务中的有效性。
5. Adversarial Speech for Voice Privacy Protection from Personalized Speech Generation
论文作者:陈世豪,陈丽萍,张结,KongAik Lee,凌震华,戴礼荣
论文单位:中国科学技术大学,新加坡理工大学
论文简介:
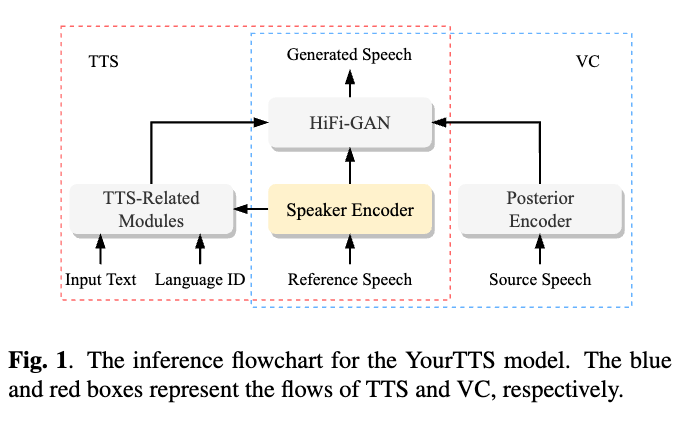
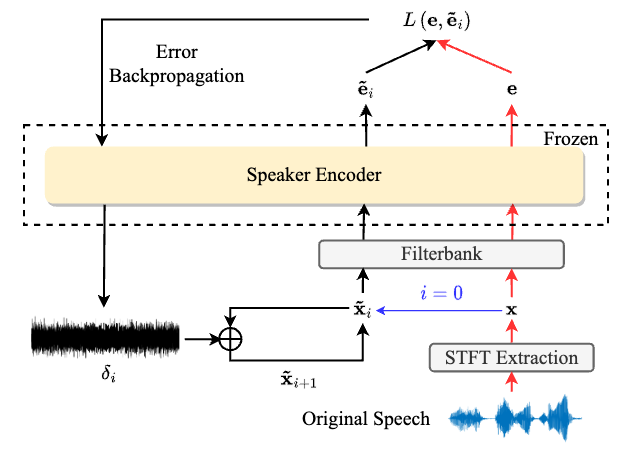
为了保护语音中的说话人信息不被提取并用于生成该说话人的仿冒语音,本文提出了一种基于对抗扰动的说话人隐私保护方法。通过给目标说话人的语音加入扰动,使得个性化语音生成模型(如文本到语音Text-to-Speech和语音转换Voice Conversion)无法生成该说话人的语音,且该噪声难以被人耳所察觉。为此,我们选取了可以同时实现个性化语音合成和声音转换的YourTTS模型为研究对象。采用I-FGSM算法,以增大扰动语音与原语音之间的说话人距离为训练目标,攻击YourTTS的说话人编码器,获得扰动语音。实验采用说话人确认(automatic speaker verification,ASV)中得到的等错误率(equal error rate,EER)作为衡量说话人保护能力的评测指标,从结果来看,在分别以原语音和扰动语音,经YourTTS生成个性化语音,并分别用作ASV测试中的注册和测试语音的实验中,得到50%左右的EER,证明了以扰动语音用作目标说话人语音,被用于个性化语音生成任务时,无法合成出原说话人的语音,该扰动生成方法达到了保护语音中的说话人信息不被用于生成仿冒语音的目的。
论文资源:Demo语音网页 https://voiceprivacy.github.io/Adeversarial-Speech-with-YourTTS
6. An End-to-End EEG Channel Selection Method with Residual Gumbel Softmax for Brain-Assisted Speech Enhancement
论文作者:徐擎天,张结, 凌震华
论文单位:中国科学技术大学
论文简介:

脑辅助语音增强(speech enhancement, SE)最近引起了越来越多的关注,因为脑电信号(EEG)在某种程度上反映了听觉注意力信息。而采用稀疏通道分布的EEG帽的设计可以节省硬件成本、装备搭建时间以及算法复杂性,这可以通过EEG通道选择来实现,因为研究表明多通道EEG信号高度相关且存在大量冗余性。因此,在本文中我们提出了一种基于加权残差结构的端到端EEG通道选择方法,称为Residual Gumbel Selection(ResGS),用于基于EEG的SE任务。加权残差连接的使用可以得到更有效和稳定的训练过程。所提出的ResGS包括加权残差训练和微调两个步骤。在公共数据集上的实验结果验证了ResGS在通道选择方面的有效性,并表明一个小的通道子集足以实现接近最优性能。
7. A Study of Multichannel Spatiotemporal Features and Knowledge Distillation on Robust Target Speaker Extraction
论文作者:汪意迟,张结,陈世豪,张为泰,叶忠义,周心远,戴礼荣
论文单位:中国科学技术大学,科大讯飞
论文简介:
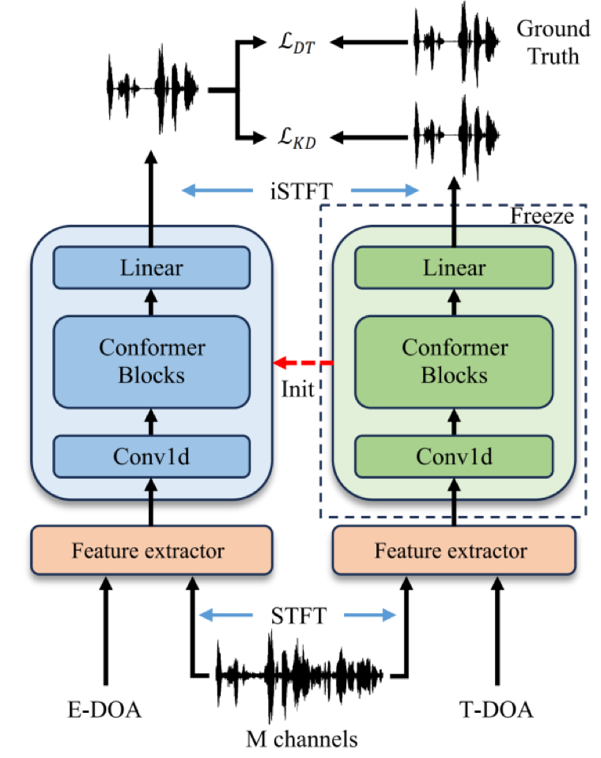
基于到达方向(direction-of-arrival, DOA)的目标说话人提取(target speaker extraction, TSE)技术,在远程会议、助听器、车载语音互动等领域有着广泛的应用。由于固有的相位不确定性,现有的TSE方法通常在特定频带内面临说话人混淆的问题。除此之外,麦克风阵列的校准不当以及环境噪声等因素导致的DOA测量不准确,也会降低TSE的性能。为了提升TSE的鲁棒性,本文提出了几种新的多通道时空特征,用以表征目标说话人的区分性。我们采用窄带Conformer模型与提出的特征相结合,以促进目标说话人的提取。此外,考虑到知识蒸馏在提升模型鲁棒性方面的作用,尤其是在DOA不匹配的情况下,我们亦对此进行了研究。公开数据集上的实验结果验证了所提出方法的有效性。
8. The Multimodal Information based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
论文作者:吴世龙, 王晨曦, 陈航,代宇盛,张辰悦,王若愚, 兰鸿博, 杜俊, 李锦辉, 陈景东, Shinji Watanabe, Sabato Siniscalchi, Odette Scharenborg, 王中秋,潘嘉, 高建清
论文单位:中国科学技术大学,佐治亚理工学院,西北工业大学,卡内基梅隆大学,恩纳大学,代尔夫特理工大学,科大讯飞
论文简介:
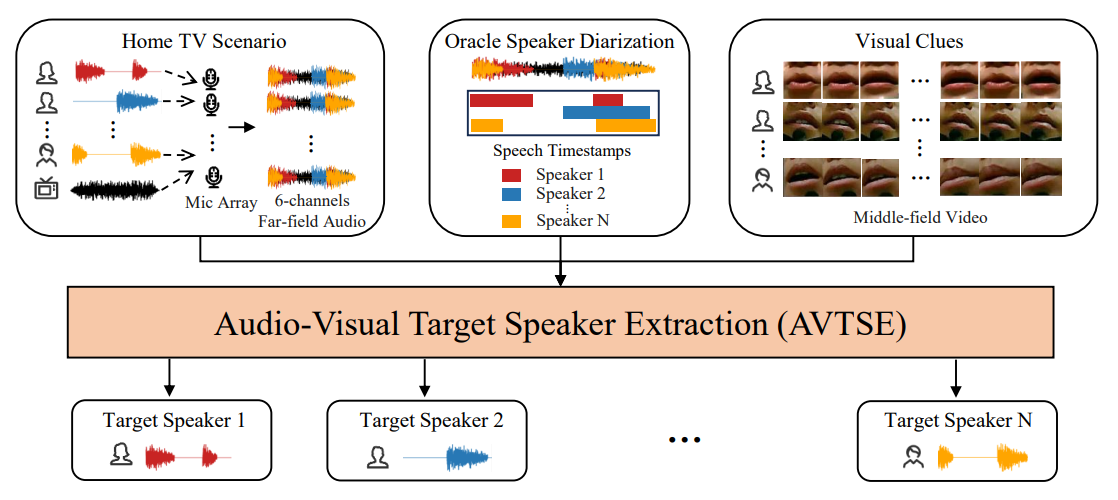
前两届基于多模态信息的语音处理(Multi-modal Information based Speech Processing, MISP)挑战赛主要聚焦于音视频语音识别(Audio-Visual Speech Recognition, AVSR),取得了值得称赞的成功。然而,由于复杂的声学环境,最先进的后端语音识别系统往往也会达到性能极限。因此,今年在ICASSP 2024 SPGC中举办的MISP 2023挑战赛将注意力转向了音视频目标说话人提取(Audio-Visual Target Speaker Extraction, AVTSE)任务。与现有的主要集中在模拟数据上的音视频语音增强比赛不同,MISP 2023挑战赛独特地探索了前端语音处理与视觉线索相结合如何影响现实世界场景中的后端任务。这项开创性的工作旨在为AVTSE任务设定第一个基准,为在具有挑战性的真实声学环境中通过AVTSE提高后端语音识别系统的准确性提供新的见解。本文对MISP 2023挑战赛的任务设置、数据集和基线系统进行了全面概述。它还包括对参与者可能遇到的挑战的深入分析。实验结果突出了这项任务的艰巨性,我们期待参与者提出创新性的解决方案。
论文资源:论文预印版下载地址:https://arxiv.org/abs/2309.08348
开源代码下载地址 https://github.com/mispchallenge/MISP-2023-Challenge-Baseline
9. Implicit Enhancement of Target Speaker in Speaker-adaptive ASR through Efficient Joint Optimization
论文作者:吴明辉,唐海桃,范佳欢,王若愚,陈航,张燕咏,杜俊,周恒顺, 孙磊 , 方昕, 高天 , 万根顺 , 潘嘉,高建清
论文单位:中国科学技术大学,科大讯飞
论文简介:

在多说话人场景中,自动语音识别(ASR)模型依赖于说话人分离后的预处理音频。然而,当目标说话人没有被准确分离时,ASR模型在达到其峰值性能方面面临限制。为了解决这一问题,我们提出了一种说话人自适应ASR框架,该框架通过高效地联合优化说话人识别(SR)和ASR模型,具有隐式增强目标说话人语音的能力。我们的框架引入了共享自监督学习表征、优化迁移和层次化说话人门控注意力模块。通过这种方式,可以最大限度地提高嵌入偏置的效果,并强调与语义单位对应的目标说话人。在CHiME-7 DASR子轨道上,与官方基线相比,该方法在开发集词错误率(WER)上实现了28.19%的相对提升。值得注意的是,这一框架也被用于CHiME-7 DASR的冠军系统。
10. Improving Multi-Modal Emotion Recognition using Entropy-Based Fusion and Pruning-based Network Architecture Optimization
论文作者:王皓天,杜俊,代宇盛,李锦辉,任玉玲,刘宇
论文单位:中国科学技术大学,佐治亚理工学院,中移在线服务有限公司
论文简介:
在本项研究中,我们的目标是在网络性能和效率上改进我们在ACM MM MER2023多模态情感识别挑战赛中获得季军的分层信息融合系统。本研究中提出的网络模型获得了在多模态情感识别MER2023数据集上的SOTA结果。
首先,我们从预训练的模型(包含HuBERT, ResNet, MANet模型)中提取鲁棒的声学和视觉表示,并将它们使用不同的结构进行多模态融合。然后,我们在本文中提出了一种基于熵的融合方法,在对所有不同特征融合结构进行多标签联合解码的基础上,获得情绪和效价的最终预测。此外,为了减少网络冗余,提高低资源多模态数据条件下的模型泛化能力,我们在本研究中提出了一种基于结构化剪枝和学习率回退的网络结构渐进式优化方法。具体的网络结构及算法流程图如下图所示:

我们的最终结果在MER 2023数据集上进行测试,结果显示基于熵融合的优化网络结构取得了显著且一致的改进。我们最终的多模态情感识别网络结构在多模态情感识别MER2023数据集上达到了SOTA结果,超过了MER- multi子挑战的冠军系统。
11. Meta Representation Learning Method for Robust Speaker Verification in Unseen Domains
论文作者:张建涛、宋彦、李晋、郭武、宋皓宇、Ian McLoughlin
论文单位:中国科学技术大学、新加坡理工大学、科大讯飞、澳大利亚国立大学
论文简介:
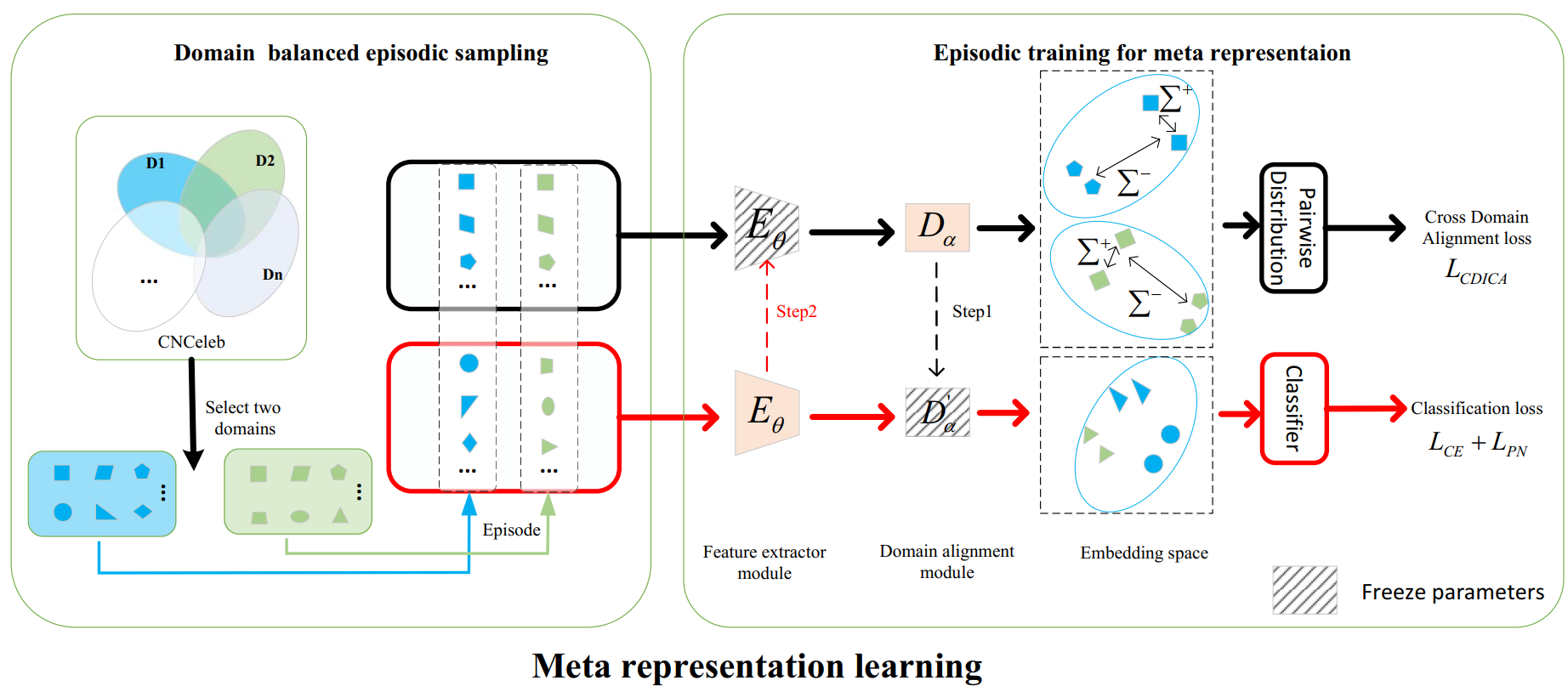
本文提出了一种元表征学习方法(Meta Representation Learning,MRL)用于解决在未知域中说话人验证(SV)的鲁棒性问题。在SV系统中,现有的嵌入学习方法很可能会受到训练集和测试集域不匹配问题带来的影响。为了解决上述问题,我们提出了一种情节化训练策略(Episodic Training)来在每个情节迭代中来模拟域不匹配情景从而提高模型对未知域的鲁棒性。在情节任务设计中,每个情节(episode)的数据是从两个不同域中进行域级别的情节平衡采样构建;在网络结构中,我们在特征提取器(FE)模块和分类器之间添加了一个额外的域对齐(DA)模块;在每个情节训练迭代中,FE和DA模块设计了不同的优化损失来训练并采用元学习优化策略分别进行参数更新来提高模型的鲁棒性。此外,我们还提出了跨域类间分布对齐(CDICA)损失来提高模型的域泛化能力。我们在CNCeleb和VoxCeleb数据集上进行了实验验证,实验结果显示我们提出的元表征学习方法在未知域的说话人识别任务中取得了显著的性能提升。
12. Generating High-Quality Adversarial Examples with Universal Perturbation-Based Adaptive Network and Improved Perceptual Loss
论文作者:李珠海,郭武,张结
论文单位:中国科学技术大学
论文简介:

基于深度神经网络的说话人识别系统容易遭受对抗攻击。然而,在大多数情况下对抗样本的失真仍然很明显。因此,本文提出了一种基于通用扰动的自适应网络(Universal Perturbation-based Adaptive Network,UPAN)来生成高质量的对抗样本。具体而言,UPAN 首先使用通用扰动生成模块生成与输入无关的扰动,然后将其输入自适应模块得到针对特定输入的扰动。最后,将生成的扰动和输入音频相加,用作攻击说话人识别系统的对抗样本。为了进一步提高语音质量,我们引入了一种改进的感知损失,它结合了输入音频和对抗样本之间的均方误差以及两者梅尔频率倒谱系数间的余弦相似度。在 VoxCeleb1 数据集上的实验结果表明,本文提出的方法对非目标攻击和目标攻击均有效。
13. Robust Spoof Speech Detection based on Multi-scale Feature Aggregation and Dynamic Convolution
论文作者:吴皓晨,张结,张震涛,赵文婷,古斌,郭武
论文单位:中国科学技术大学,中国招商银行
论文简介:
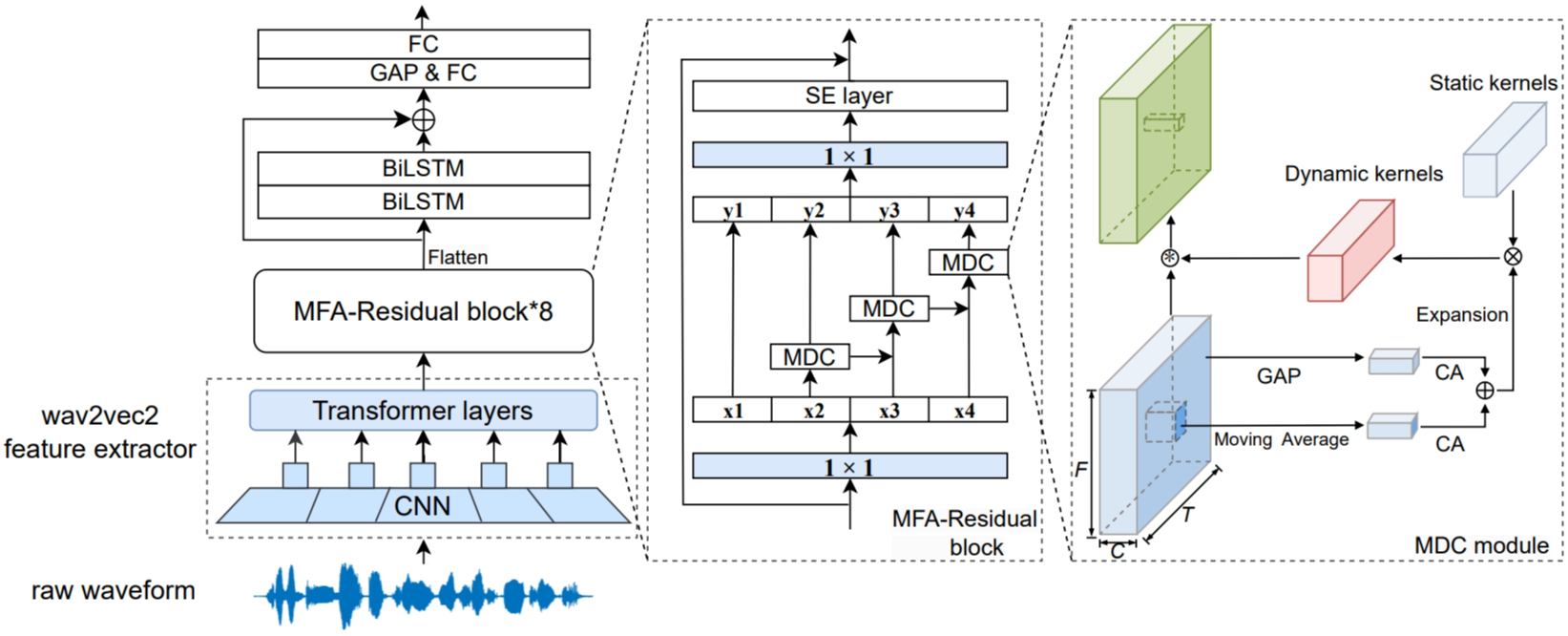
伪造语音检测(SSD)可以帮助保护自动说话人识别系统免受恶意攻击。然而,不同的语音合成和语音转换算法生成的伪造语音存在很大差异,这导致SSD系统对未知欺骗攻击的通用性较差。为了解决这个问题,我们将多尺度特征聚合(MFA)和动态卷积操作集成到伪造语音检测的框架中,以检测未知欺骗攻击的不同局部和全局伪影。提出的框架主要包含八个堆叠的MFA块,其中每个MFA块中都使用light-Res2Net模块来提取多尺度特征,其卷积核由输入的局部和全局统计信息动态生成。在两个基准数据集(即ADD 2023 Fake Audio Detection和ASVspoof 2021 Logical Access)上的结果表明,所提出的方法优于现有的最先进的系统。
14. Neural Speaker Diarization using Memory-Aware Multi-Speaker Embedding with Sequence-to-Sequence Architecture
论文作者:杨高斌,何茂奎,牛树同,王若愚,岳颜颜,钱双庆,吴世龙,杜俊,李锦辉
论文单位:中国科学技术大学,科大讯飞,佐治亚理工学院
论文简介:
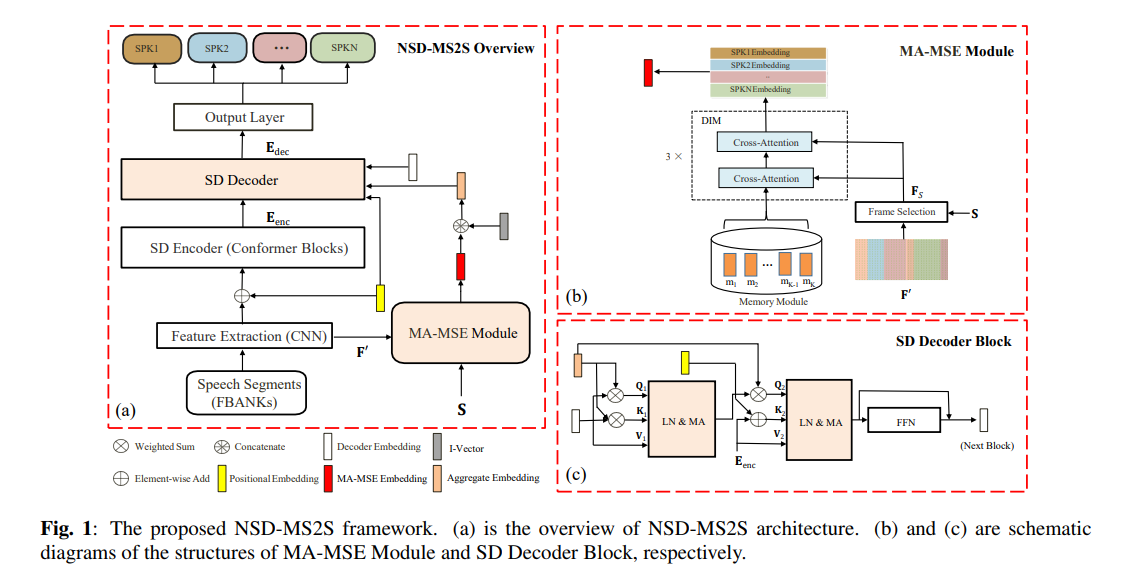
本文提出了一种基于序列到序列结构(NSD-MS2S)的记忆感知多说话者嵌入神经系统,该系统集成了记忆感知多说话者嵌入(MA-MSE)和序列到序列(Seq2Seq)结构的优点,从而提高了系统的效率和性能。接下来,我们结合输入特征融合进一步减少解码的内存占用,然后采用多头注意机制捕获不同层次的特征。NSD-MS2S在CHiME-7的EVAL集上实现了15.9 DER,比官方基准系统提高了49 %,是我们在CHiME-7 DASR挑战赛的主道上获得第一名的关键技术。此外,我们在MA-MSE模块中引入了深度交互模块(DIM),以更好地检索更清晰、更具判别性的多说话人嵌入,进一步提高我们的模型性能。
论文资源:论文预印版下载地址: //arxiv.org/abs/2309.09180
即将开源:https://github.com/liyunlongaaa/NSD-MS2S
15. A Spatial Long-Term Iterative Mask Estimation Approach for Multi-Channel Speaker Diarization and Speech Recognition
论文作者:马峰, 屠彦辉, 何茂奎, 王若愚, 牛树同, 孙磊, 叶中付, 杜俊, 潘嘉, 李锦辉
论文单位:中国科学技术大学,科大讯飞,佐治亚理工学院
论文简介:

与传统的基于聚类的说话人日志方法相比,基于深度学习的说话人日志方法在远场下对多说话人日志和语音识别具有更好的性能。然而,由于对未知阵列拓扑和声学场景的稳健性较差,大多数基于深度学习的方法不能很好地利用空间信息。本文提出了一种基于空间信息的长时迭代掩码估计(SLT-IME)方法,以提高说话人日志在各种真实声学场景中的性能。首先,利用日志结果为初始值的复角中心高斯混合模型(CACGMM)来估计每个说话人在每个时频区间的存在概率,即说话人掩码在长时块中的存在概率。然后,根据阈值将说话人掩码转换为说话人活动,从而传递出哪个说话人正在活动以及何时活动的日志信息。最后,估计的说话人活动也可以作为说话人日志系统的初始输入,从而提高ASR性能。在CHME-7三个数据集(CHME-6,DiPCo,Mixer 6)上的实验结果表明,该方法可以同时提高说话人日志和语音识别系统的性能。在CHiME-7 DASR挑战赛主赛道取得最佳表现的融合系统中,它扮演着关键角色。
16. DP-MAE: A Dual-Path Masked Autoencoder based Self-Supervised Learning Method for Anomalous Sound Detection
论文作者:刘卓立、宋彦、曾晓敏、戴礼荣、Ian McLoughlin
论文单位:中国科学技术大学、新加坡理工大学
论文简介:

本文提出了一种用于异常声音检测的通用音频表征学习方法,称为双通道掩码自动编码器(Dual-Path Masked Autoencoder,DP-MAE)。现有的异常声音检测方法主要集中于帧级生成式方法和段级判别式方法,这些方法忽略了更容易出现异常模式的局部信息。此外,它们在异常声音检测任务上使用不同的系统,缺乏表征的通用性。针对这些问题,所提出的DP-MAE提取patch级别的特征,学习具有更好泛化性的统一音频表征。该方法通过自监督表征学习方法建模对异常检测有利的局部信息,增加了微调过程中段级表征的信息量。具体而言,输入的谱图被随机划分为两个patch级别的子集,输入DP-MAE中互相预测。同时,模型引入自蒸馏概念,将一个路径的输出视为另一个路径的预测目标。在微调阶段,线性分类器被应用于DP-MAE生成的特征,获得更紧凑的正常音频表征。在DCASE2022 Task2开发集上的实验证明了DP-MAE的有效性。
17. Multiscale Matching Driven by Cross-Modal Similarity Consistency for Audio-Text Retrieval
论文作者:王芊,顾佳宸,凌震华
论文单位:中国科学技术大学
论文简介:

针对音频文本检索任务的传统框架通常将两种模态的信息分别转换成单个全局向量以直接匹配,这些方法忽略了细节信息,难以捕捉模态间错综复杂的匹配关系。因此,我们建立了新的框架,从多尺度和多角度两个方面深入挖掘多模态信息的匹配关系。首先,我们提出了从局部-局部,局部-全局到全局-全局逐级递进的多尺度匹配方法,实现了细粒度的跨模态潜在对齐。此外,我们创新利用了模态间与模态内部的相似度一致性的原则,以模态内部的相似关系作为额外的软监督,进一步促进模态间的对齐。实验表明我们的方法在AudioCaps/Clotho数据集上,进行基于文本的音频检索任务时R@1(召回率)分别提升了3.9%/2.9%,进行基于音频的文本检索任务时R@1分别提升了6.9%/5.4%。
18. Viewing Writing as Video: Optical Flow based Multi-Modal Handwritten Mathematical Expression Recognition
论文作者:程翰博,杜俊,胡鹏飞,马洁锋,张镇荣,薛莫白
论文单位:中国科学技术大学
论文简介:

本文研究了多模态的手写数学公式识别(HMER)算法。多模态的HMER 算法同时应用了在线和离线两种模态,即动态轨迹点序列和静态图像,对数学公式输入进行识别并生成对应的LaTeX序列。然而,由于在线和离线两种模态之间存在异质性,这导致了它们的对齐和融合过程中存在挑战。在这项工作中,我们将书写过程视为一个视频,并引入了聚合光流图(AOFM)来表示在线模态,这与离线模态更加兼容。另外,我们提出了光流感知网络(OFAN),以便自动提取、对齐和融合在线和离线模态之间的特征。通过实验分析,我们的方法可以可插拔地应用于多个现有的离线HMER模型,从而在CROHME 2014、2016和2019数据集上产生稳定且显著的性能提升。
论文资源:开源代码:https://github.com/Hanbo-Cheng/OFAN.git