

近日,Interspeech 2026会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共14篇论文被会议接收,论文方向涵盖语音编码、语音合成、语音识别、语音匿名化、声音事件检测等,各接收论文简介见后文。
Interspeech是由国际语音通信协会(ISCA)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会。本届会议以“Speaking Together”为主题,内容涵盖语音识别、语音合成、语音编码、语音增强、自然语言处理等多个领域。
1. An Ultra-Low-Bitrate Neural Speech Codec with Plain-to-Pseudo Synergistic Vector Quantization
论文作者:江晓航,艾杨,刘飞,郑瑞晨,高建清,凌震华,吴及
论文单位:中国科学技术大学,科大讯飞,清华大学
论文简介:
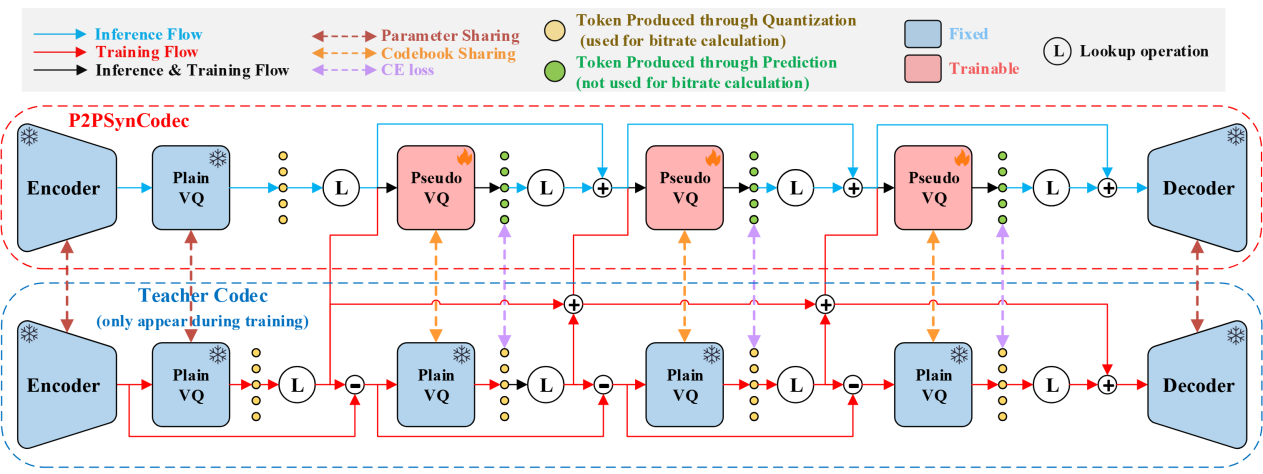
针对现有神经语音编解码器普遍依赖残差矢量量化器(residual vector quantizer,RVQ)、后续量化器消耗相同码率但信息贡献逐渐降低的问题,本文提出一种超低码率神经语音编解码器 P2PSynCodec。该模型的核心是明码到伪码协同矢量量化器(plain-to-pseudo synergistic vector quantizer,P2PSVQ),由一个基础矢量量化器(plain VQ)和多个伪矢量量化器(pseudo VQ)构成。其工作流程如下:首先,编码器将输入语音转换为压缩后的声学表征,并由基础矢量量化器生成用于实际传输或存储的基础表征序列;随后,伪矢量量化器根据基础表征序列预测辅助表征序列,从而在不增加传输码率的情况下补充语音重构所需的信息;最终,解码器整合基础表征与预测得到的辅助表征,重构语音波形。在模型训练阶段,P2PSynCodec 采用基于教师编解码器的两阶段训练策略,通过教师强制和交叉熵损失学习伪量化器的表征预测能力。由于实际传输过程中仅需传输基础矢量量化器产生的 token,P2PSynCodec 能够显著降低码率。实验结果表明,P2PSynCodec 在仅 0.5 kbps 的超低码率下,能够获得与 2.0 kbps 级别神经语音编解码器相近的主观语音质量,实现约 75% 的码率节省。
论文资源:预印版网址 https://arxiv.org/abs/2606.05876
Demo语音网页 https://pb20000090.github.io/P2PSynCodec/
2. VoCodec: A Low-bitrate Streamable Neural Speech Codec with Voicing-driven Quantization
论文作者:江晓航,艾杨,郑瑞晨,戴礼荣,凌震华,吴及
论文单位:中国科学技术大学,清华大学
论文简介:
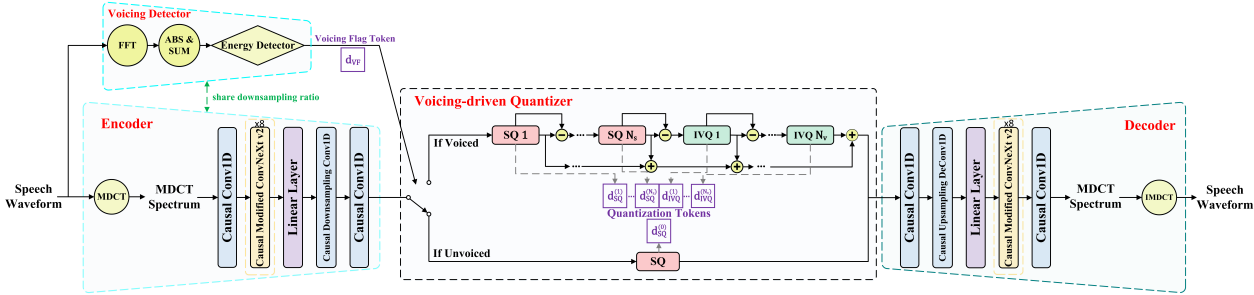
本文聚焦低码率实时语音压缩场景,旨在在有限带宽和低延迟要求下实现高质量语音传输与存储,可广泛应用于实时语音通信、在线会议、移动端语音交互及低带宽语音服务等领域。针对现有神经语音编解码器通常对所有语音帧采用统一量化策略、难以根据语音内容重要性灵活分配码率的问题,本文提出一种基于清浊音驱动量化的流式神经语音编解码器 VoCodec。该模型由全因果编码器、清浊音检测器、清浊音驱动量化器和解码器构成。其工作流程如下:首先,编码器将输入语音转换为压缩后的声学表征,同时清浊音检测器判断每一帧语音的清浊属性;随后,清浊音驱动量化器根据检测结果自适应选择量化方式,对感知上更重要的浊音帧采用更精细的残差标量-矢量量化器(residual scalar-vector quantizer,RSVQ),对感知影响相对较弱的非浊音帧采用更简单的标量量化器(scalar quantizer,SQ);最终,解码器根据量化后的表征重构语音波形。由于 VoCodec 能够将更多码率分配给携带主要语音信息的浊音部分,并减少非浊音部分的冗余开销,该模型在保持流式处理能力和较低复杂度的同时,有效提升了低码率语音压缩效率。实验结果表明,VoCodec 在 16 kHz 采样率、仅 1.1 kbps 的低码率条件下,仍能取得优于多种基线神经语音编解码器的重构质量;进一步实验也验证了清浊音驱动量化策略相比统一量化策略可实现约 27% 的码率节省。
论文资源:预印版网址 https://arxiv.org/abs/2606.05892
Demo语音网页 https://pb20000090.github.io/VoCodec/
3. Beyond WER: A Paired Acoustic Stress Test for Ambient Clinical Scribes
论文作者:江晓航,郭瀚杰,梁颖思,艾杨,凌震华,姜磊,贺志阳
论文单位:中国科学技术大学,科大讯飞
论文简介:
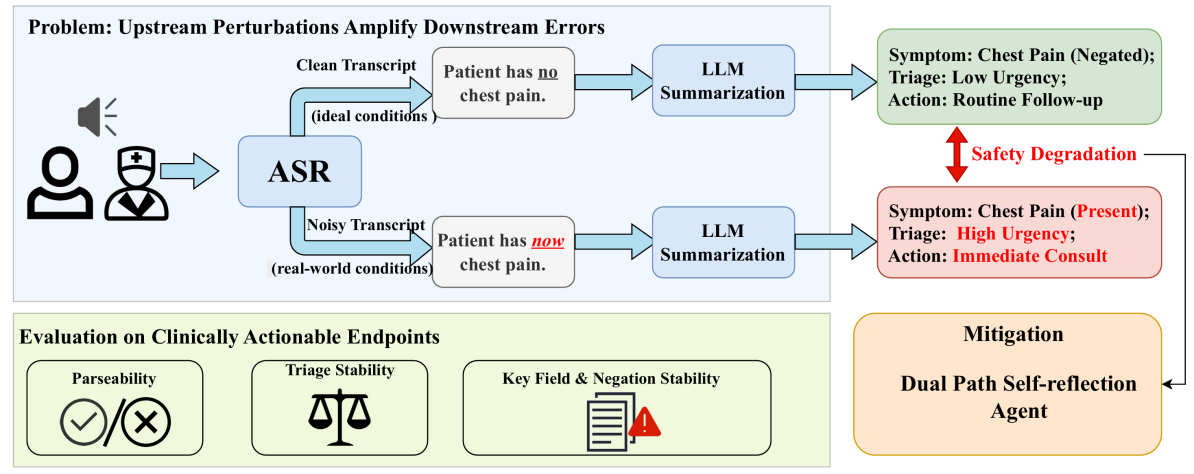
本文聚焦环境临床记录系统中的语音识别误差传播问题,旨在评估真实噪声环境下自动语音识别与大语言模型级联系统的临床安全性。随着自动语音识别(automatic speech recognition,ASR)和大语言模型(large language model,LLM)逐渐被用于医生—患者对话记录、结构化病历生成和临床辅助决策,传统词错误率(word error rate,WER)已难以充分反映系统在临床场景中的潜在风险。针对这一问题,本文提出一种成对声学压力测试框架,用于分析不同声学扰动如何影响下游临床语义理解与安全判断。该框架以同一段临床对话为基础,分别构造干净语音和加入不同类型噪声后的语音版本,并在保持下游大语言模型配置不变的条件下,比较噪声引起的临床输出变化。本文重点考察两类常见声学干扰:一类是诊室、设备等产生的平稳环境噪声,另一类是候诊区或多人交谈场景中的非平稳语义干扰。实验进一步构建了从上游识别错误到下游安全后果的分析体系,关注否定词丢失、数字或单位错误、背景语音污染等高风险触发因素,以及红旗症状遗漏、分诊等级变化和不安全输出等临床结果。实验结果表明,WER 的轻微变化并不意味着系统安全性保持稳定;即使在词错误率变化很小的情况下,噪声也可能显著增加不安全临床输出。进一步地,本文提出一种轻量级的证据约束缓解策略,通过要求模型输出可追溯的原文证据并过滤缺乏依据的高风险内容,在无需微调模型的情况下减轻噪声条件下的安全退化。该研究表明,面向临床语音智能系统的评估不应仅停留在转写准确率层面,而应进一步关注声学扰动对临床语义和患者安全的实际影响。
论文资源:预印版网址 https://arxiv.org/abs/2606.05909
4. CycleCodec: Distillation-Free Factorized Neural Speech Codec via Cycle-Consistent Speaker Swapping
论文作者:郑瑞晨,Nicholas Sanders,Jinzuomu Zhong,艾杨,凌震华,Korin Richmond
论文单位:中国科学技术大学、英国爱丁堡大学
论文简介:
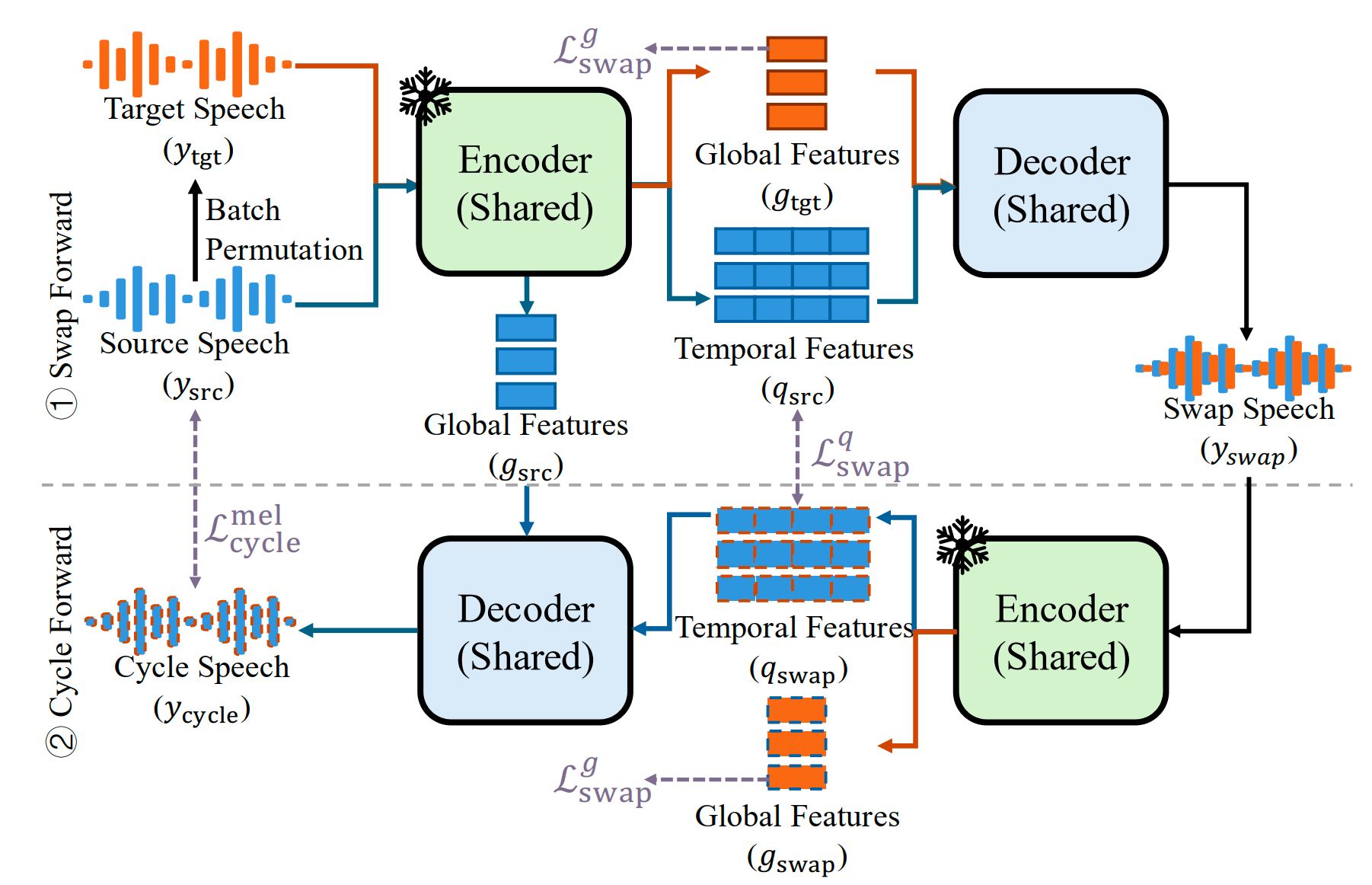
本文聚焦神经语音编解码器中的语音内容与说话人信息解耦问题,旨在摆脱对预训练自监督学习模型或自动语音识别系统的依赖,实现无需知识蒸馏的内容—说话人表征解耦。针对这一问题,本文提出一种从零训练的解耦神经语音编解码器CycleCodec。该模型将语音分解为帧级离散时间变化表征和句级全局说话人表征,分别用于刻画语音内容和说话人特征。CycleCodec的核心机制是循环一致说话人交换:模型先将源语音的内容表征与目标语音的说话人表征组合生成交换语音,再对交换语音重新编码,并在换回源说话人条件后重建源语音,从而在编解码器内部形成自监督约束,减少内容流与说话人流之间的信息泄漏。与此同时,CycleCodec通过限制时间变化流的码本容量、引入基于查询的Transformer聚合器以及说话人对比损失,进一步提升说话人建模和表征解耦能力。实验结果表明,在仅使用英语语音训练的情况下,CycleCodec在英语、普通话和越南语测试集上均优于无需蒸馏的基线模型TiCodec,并在语音重建和零样本语音转换任务中表现出更稳定的内容保持与说话人控制能力。。
论文资源:Demo 语音网页 https://zhengrachel.github.io/CycleCodec/
5. Reducing Speaker Residual by Considering Pinhole Effect in Voice Anonymization
论文作者:刘泽彦,姜玮丽,陈丽萍,Kong Aik Lee,赵博宇,高凯,凌震华
论文单位:中国科学技术大学,香港理工大学,公安部鉴定中心
论文简介:
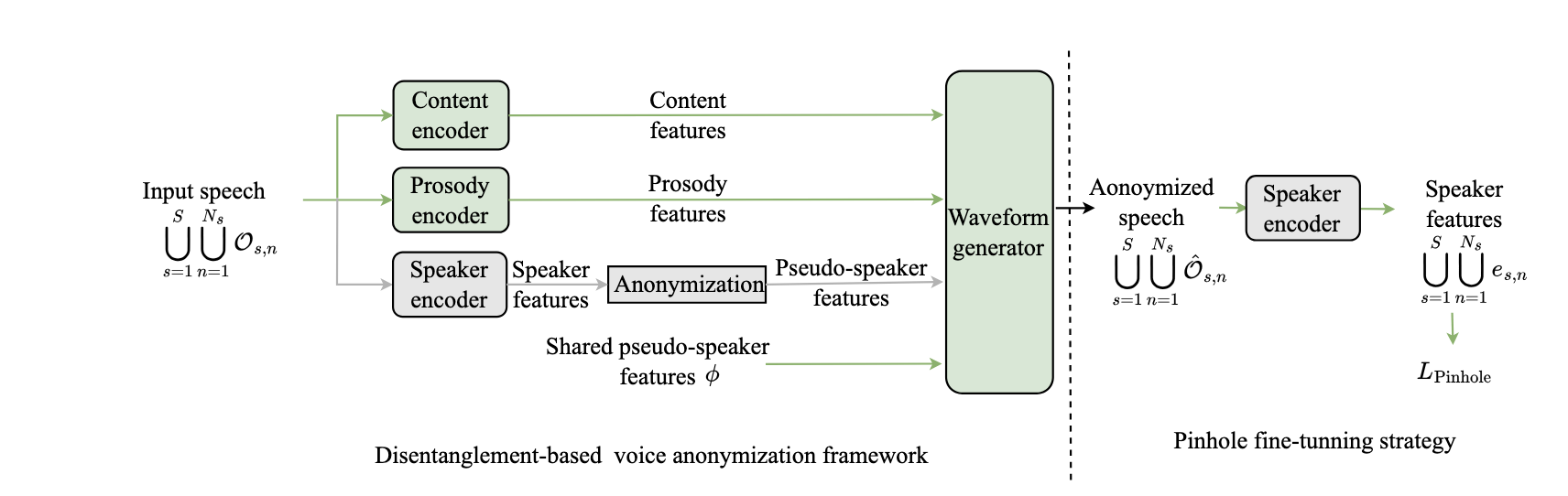
语音匿名化技术旨在保护说话人隐私,其在通过修改说话人身份信息以阻止身份识别的同时,保留语音中的语言内容与韵律信息。然而,受限于现有解耦表示的
完美性,匿名化后的语音表征中仍残留与原说话人相关的属性,使得来自同一源说话人的匿名语音之间依然具有可连接性,从而削弱了隐私保护效果。针对这一问题,本文提出一种基于针孔效应(pinhole effect)的微调策略,用于在已训练好的语音匿名化框架上进一步降低残留说话人属性。本文方法基于 Pinhole effect on linkability and dispersion in speaker anonymization, IEEE Signal Processing Letters, 2025 中提出的针孔效应理论:在多对一映射下,所有源说话人被投射到同一伪说话人,理想情况下源说话人属性应被完全抹除并坍缩到该共享伪说话人;而残留属性越大,匿名语音越易按源说话人聚类,可连接性越强。受此启发,本文将该可连接性定义为针孔损失(pinhole loss),用类内方差与类间方差之比来度量同源匿名语音的聚集程度,并以此为监督信号在多个语音匿名化框架上进行微调,从而抑制内容与韵律表征中的残留说话人属性。本文在不同的匿名化框架(如基于 x-vector、ASRBN、ASRBN-GST 等)以及不同的伪说话人生成策略(any-to-one、随机选择、GAN、IDMap-Diff)上开展了系统实验,并通过说话人验证、说话人泄漏探针、自动语音识别和情感识别等多维度评测进行综合分析。实验结果表明,该微调策略能够在保持语音可懂度和情感保真度的前提下,一致地提升多种语音匿名化框架的隐私保护能力,为现有语音匿名化系统提供了一种通用、即插即用的隐私增强方案。
论文资源:Demo语音网页 https://anonymous.4open.science/r/Pinhole-loss-fine-tunning-4628
6. DuraMark: Duration-Embedded Watermarking in LLM-based TTS
论文作者:牟真伟,姜玮丽,陈丽萍,凌震华,Kong Aik Lee,高凯,赵博宇
论文单位:中国科学技术大学;香港理工大学;公安部物证鉴定中心
论文简介:
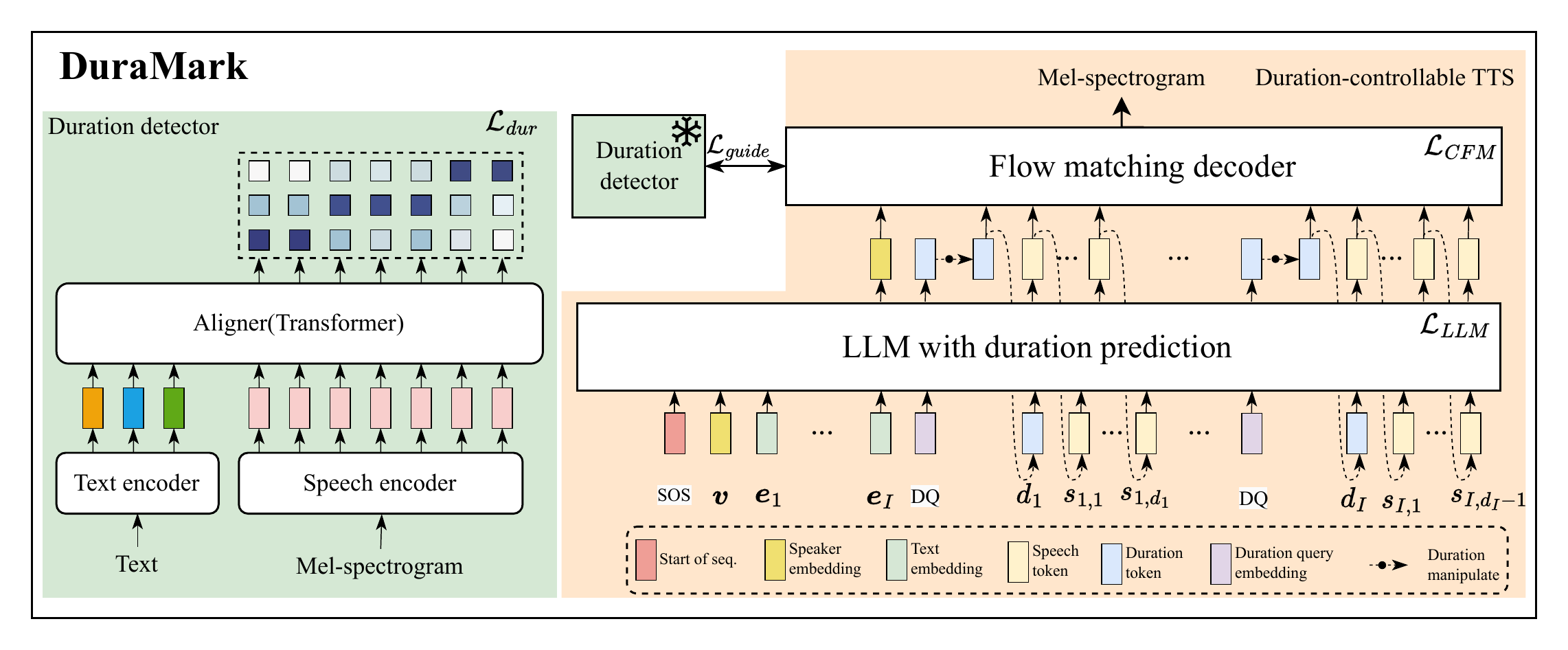
本文聚焦大语言模型文本转语音(LLM-based TTS)技术快速发展背景下的生成式语音内容溯源问题。随着语音克隆模型在自然度和说话人相似度方面持续提升,深度伪造语音的滥用风险也随之增加,语音水印因此成为区分和追踪合成语音的重要技术。现有主流方法大多在波形或频谱等信号层面嵌入水印,面对神经音频编解码器、神经声码器等重合成攻击时,水印信息容易被平滑或破坏。针对这一问题,本文提出一种信息层语音水印框架 DuraMark。该方法首先构建可显式控制音节时长的 LLM-based TTS 模型,在合成阶段通过编辑音节时长将二进制水印嵌入到语音的时长序列中;随后利用时长提取器从待检测语音中恢复音节时长,并通过与目标水印序列的相关性完成检测。实验结果表明,DuraMark 在神经编解码器、神经声码器、语音增强、有损压缩和常规信号处理等多类攻击下均表现出稳定的检测性能,在生成式重合成攻击场景中显著优于 AudioSeal、Timbre 和 WavMark 等信号层基线方法,平均检测真阳性率达到 0.993(已知文本)和 0.978(盲检测)。同时,自然度评测结果表明,该方法在嵌入水印后基本保持了语音可懂度和自然度,为生成式语音内容的可靠标识与溯源提供了新的技术思路。
论文资源:Demo语音网页 https://muzw.github.io/duramark_demo/
7. Dynamic Prosody Prediction in LLM-based TTS for Improving Speaker Similarity
论文作者:牟真伟,陈丽萍,胡亚军,凌震华,方昕,高建清
论文单位:中国科学技术大学;科大讯飞
论文简介:
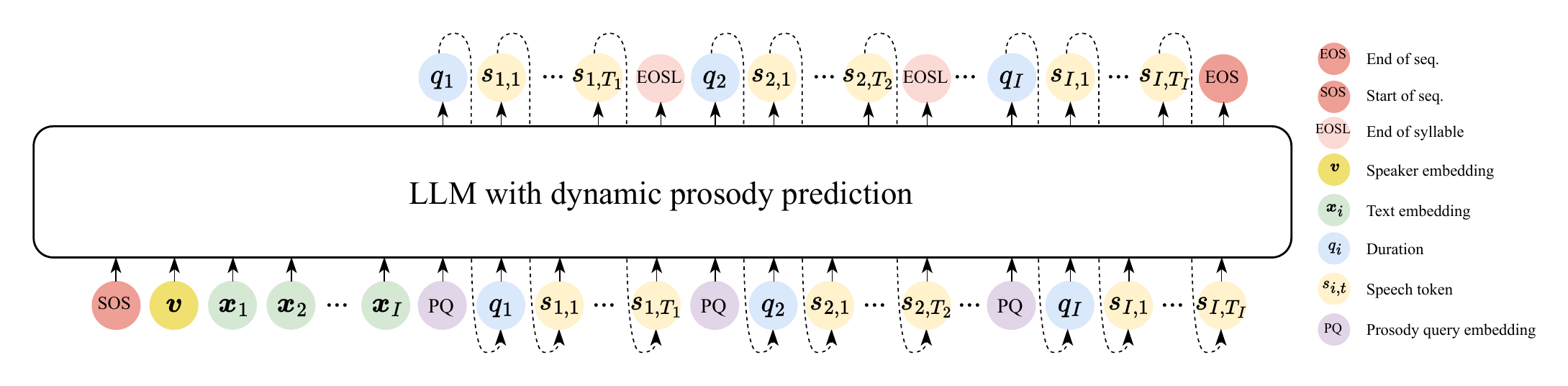
本文聚焦个性化文本转语音(TTS)中的说话人相似度提升问题。个性化 TTS 不仅需要复现目标说话人的音色,还需要模仿其说话风格,而韵律正是表达风格的重要载体。现有 LLM-based TTS 方法通常从参考语音中整体建模说话人属性,或在生成前一次性预测整句韵律,难以充分捕捉目标文本与已生成语音共同决定的动态韵律变化,从而限制了合成语音与目标说话人的相似度。针对这一问题,本文提出一种动态韵律预测方法:在逐音节生成语音的过程中,模型会在生成当前音节的语音 token 之前,基于目标文本、参考语音以及此前已经生成的目标语音,动态预测当前音节的韵律 token,并将其作为条件参与后续语音生成。该方法将音节级时长、能量、基频及基频范围等特征量化为韵律 token,使模型能够在合成过程中显式学习和传递说话风格。实验在 ESD、科大讯飞内部数据集和 AISHELL-3 三个中文测试集上开展,结果表明,该方法在保持语音自然度的同时,提高了主观说话人相似度偏好,并在字符错误率、情感相似度、基频和能量相关性等客观指标上取得更优表现。与 CosyVoice、CoT 韵律预测方式以及 Vevo1.5、F5-TTS 等开源模型的比较进一步说明,动态韵律预测能够增强 LLM-based TTS 的韵律建模能力,尤其有助于缩小小规模与大规模训练数据之间的风格学习差距。
论文资源:Demo语音网页 https://muzw.github.io/dynapros/
8. CoSTA: Cognitive-State-Conditioned TTS Data Augmentation Using ASR Transcripts for Alzheimer’s Disease Detection
论文作者:刘寅龙,李远超,王一鸣,李玥,冯锐,陈佳鑫,刘少博,何浏,陈雨昂,袁家宏,凌震华
论文单位:中国科学技术大学,爱丁堡大学
论文简介:
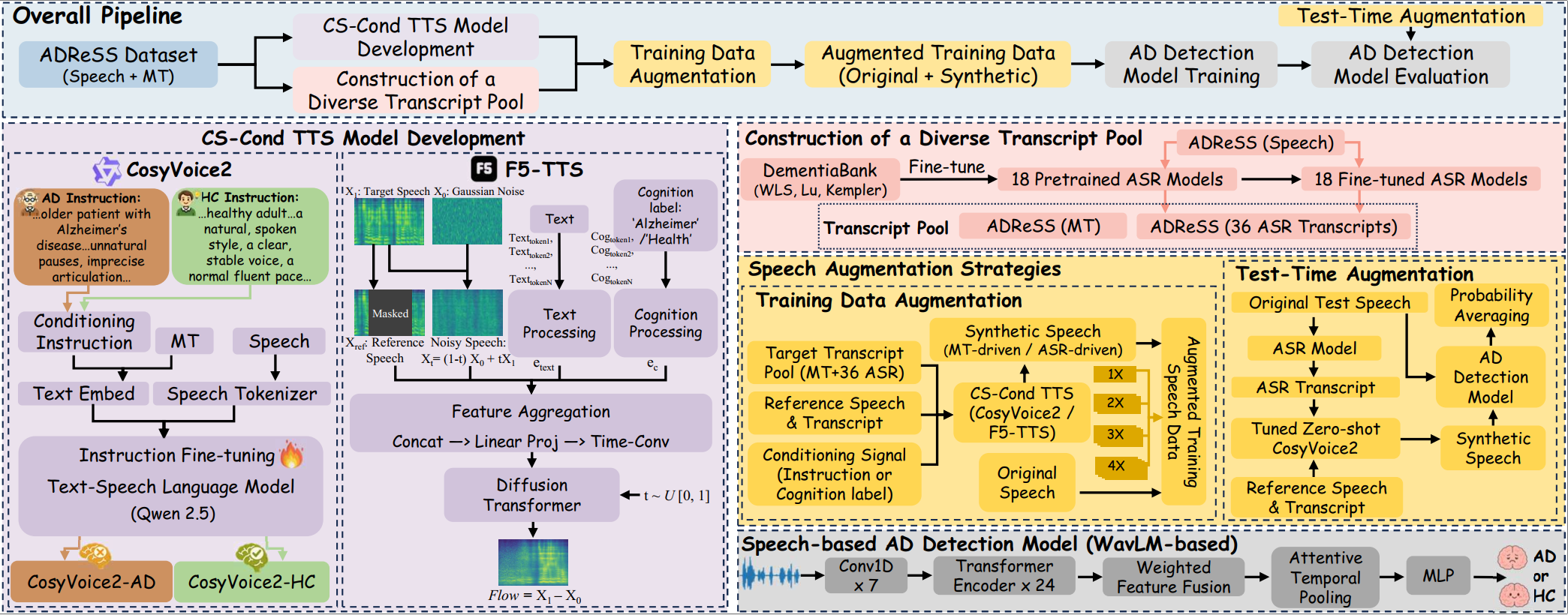
基于语音的阿尔茨海默病(Alzheimer’s Disease,AD)检测具有广阔的应用前景,但其长期受到语音数据稀缺的限制。为缓解这一问题,我们提出了基于文本转语音(Text-to-Speech,TTS)的数据增广框架 CoSTA。具体而言,我们首先对 CosyVoice2 和 F5-TTS 这两个预训练的TTS模型进行适配,构建了两种认知状态条件可控(Cognitive-State-Conditioned, CS-Cond)的TTS模型,其能够分别合成具有阿尔茨海默病患者和健康对照(Healthy Control, HC)特征的语音数据。进一步,我们构建了由人工转录文本(Manual Transcripts, MT)和 36 种自动语音识别(Automatic Speech Recognition, ASR)转录文本组成的转录池,系统研究了不同文本来源对 TTS 数据增广效果的影响。同时,我们还进行了增广倍数分析(augmentation-factor analysis)和测试时增广(test-time augmentation)实验。在 ADReSS 数据集上的实验结果表明,认知状态条件可控的TTS 显著提升了合成语音在阿尔茨海默病检测任务中的应用价值;同时,基于 ASR 转录文本的数据增广方案在多数情况下优于基于人工转录文本的增广方案。最终,CoSTA 相较于基线模型取得了 4.16% 的性能提升,在 ADReSS 测试集上实现了 85.83% 的仅音频检测准确率,并超过了现有方法的性能表现。
论文资源:预印版网址 http://arxiv.org/abs/2606.06170
9. Consistency-Regularized Dual-Branch Network with Performance-Aware Mean Teacher for Sound Event Detection
论文作者:戴礼鹏,王青,郭武,高鹏,章智军,李奎良,付金杰
论文单位:中国科学技术大学
论文简介:
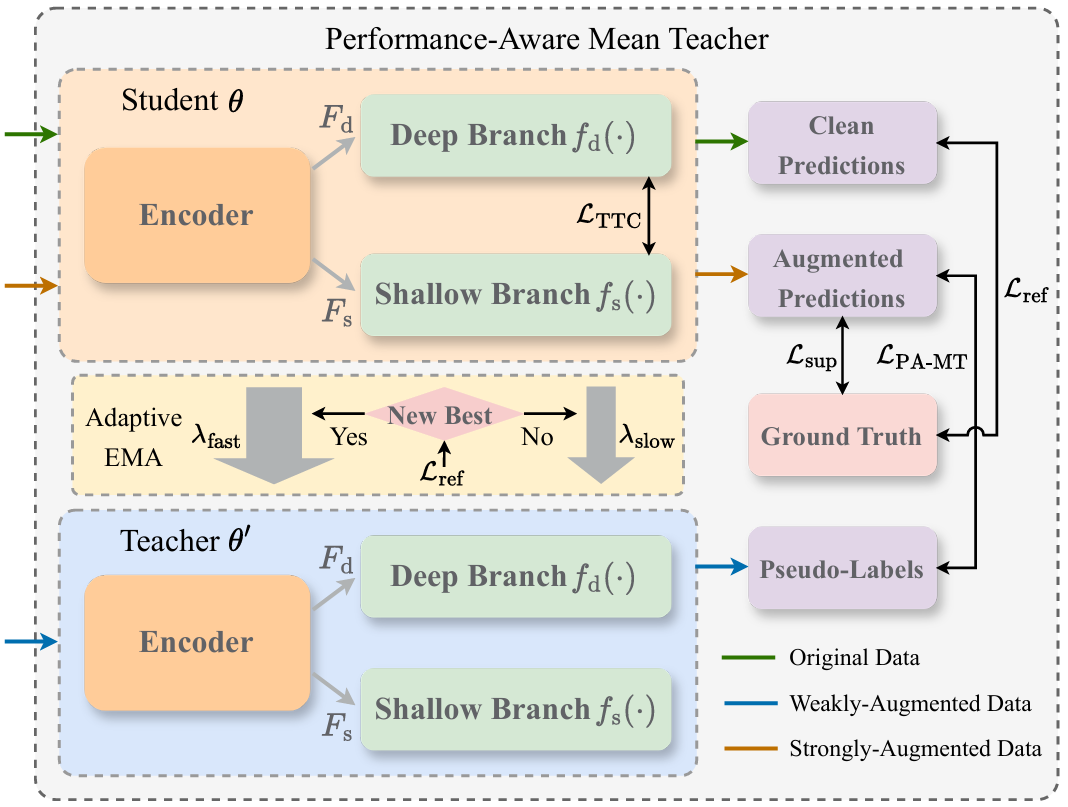
在本文中,我们提出了一种增强基于预训练模型的声音事件检测(SED)方法。该模型架构包含一个预训练的ATST(Audio Teacher-Student Transformer)前端,以及一个分别对ATST的浅层和深层特征进行建模的级联双分支后端。为了捕捉更具辨识度的线索,我们提出了时间拓扑一致性(Temporal Topological Consistency,TTC)损失,用于对齐双分支特征的时间结构。在模型训练方面,我们提出了性能感知均值教师(Performance-Aware Mean Teacher,PA-MT)框架,该框架采用自适应指数移动平均(Exponential Moving Average,EMA)策略,根据学生模型的性能来动态调整教师模型的更新幅度,从而确保模型更新的稳定性。此外,我们还采用了跨阶段融合(Cross-Stage Fusion,CSF)策略来结合不同训练阶段的优势。在DCASE 2024挑战赛任务4的验证集上,实验结果证明了所提出方法的优越性。
10. Towards Fine-grained Temporal Perception: Post-Training Large Audio-Language Models with Audio-Side Time Prompt
论文作者:史彦峰,蔡鹏飞,刘骏,顾庆,江南,戴礼荣,Ian McLoughlin,宋彦
论文单位:中国科学技术大学,新加坡理工大学
论文简介:
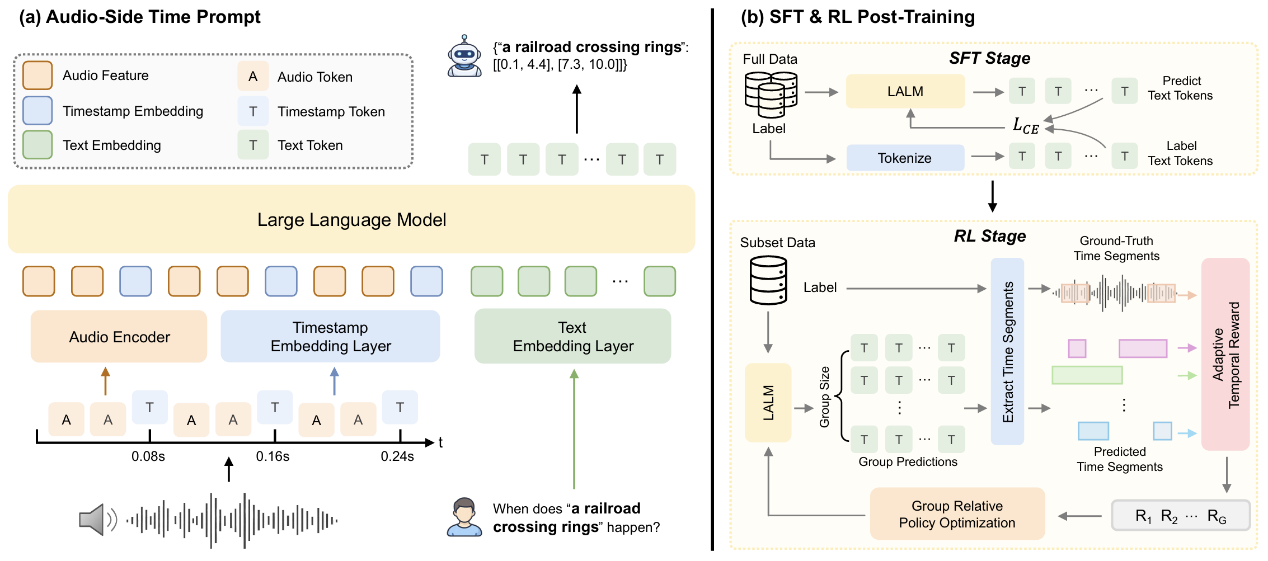
大型音频语言模型(LALM)在通用音频理解任务中表现突出,但在细粒度时间感知方面仍存在不足。为了解决这
一问题,本文提出了 TimeProRL 框架。具体而言,本文设计了 AudioSide Time Prompt,将时间戳编码为
Timestamp Embedding,并插入到音频特征序列中,使模型在音频侧获得显式的时间坐标提示;同时,在监督微调
(SFT)之后引入基于 GRPO 的强化学习后训练,并设计了自适应时间奖励机制,将时间对齐质量转化为奖励信号,
从而缓解 token-level 交叉熵损失与时间边界预测偏差不匹配的问题。实验结果表明,TimePro-RL 在音频
Grounding、声音事件检测和密集音频字幕三个任务上均优于零样本和 SFT 基线,验证了音频侧时间提示与强化学习
后训练对细粒度时间感知的有效性。消融实验进一步证明,时间戳嵌入的语义初始化和自适应时间奖励机制对性能提
升均发挥关键作用。
论文资源:https://arxiv.org/abs/2604.13715
11. A Semantic-Anchor-based Method for Open-Vocabulary Sound Event Detection
论文作者:刘骏,蔡鹏飞,史彦峰,顾庆,江南,戴礼荣,宋彦
论文单位:中国科学技术大学
论文简介:
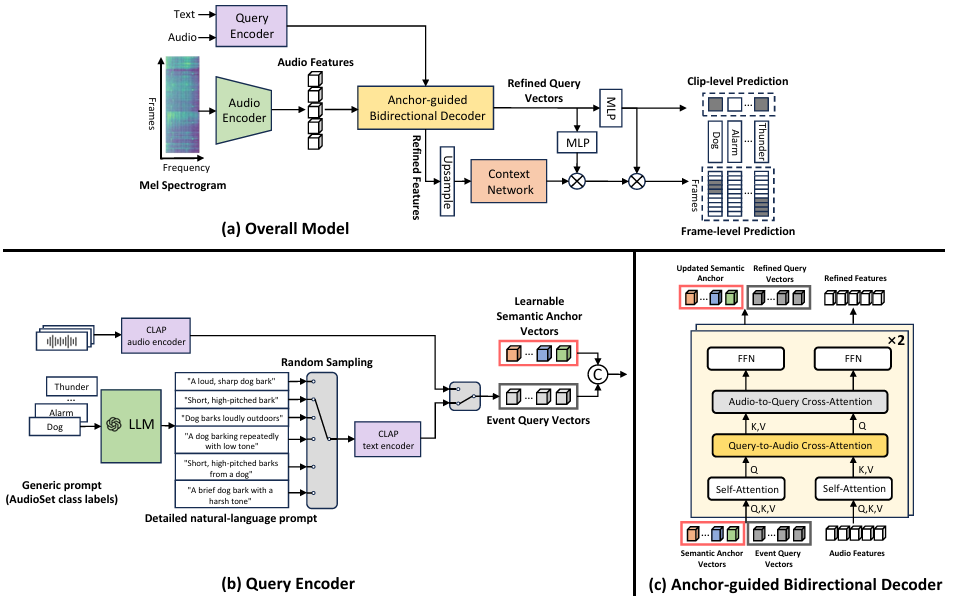
基于查询的开放词汇声音事件检测(SED)在超越封闭集模型方面具有前景。然而,大多数方法仅使用查询向量进行检索,而没有对事件的语义进行理解,从而限制了对新类别的识别。为了解决这个问题,我们提出了一种基于语义锚点的方法。具体而言,我们学习了一组Semantic-Anchor vector,作为语义层面的参考标记,从而可以通过关注这些锚点更好地理解任意事件。我们还引入了双向注意力以增强查询与特征的交互,从而实现更有效的检索,并设计了定制的查询增强以提高鲁棒性。在 AudioSet-Strong 上的实验表明,在识别新类别方面准确率优越,在开放词汇设置下取得了 34.9 的 PSDS,超过了此前的开放词汇 SED 模型。此外,在 DESED 上的跨数据集评估验证了我们方法的强泛化能力。在零样本情况下,我们实现了 44.1 的 PSDS1,超过了 DESED 官方基线。
12. MCA-DCF-DS: An Adaptive Framework for Unified Diarization and Separation with Spatial Information
论文作者:牛树同,王若愚,杨高斌,姜娅,高天,潘嘉,杜俊
论文单位:中国科学技术大学 / 科大讯飞研究院
论文简介:
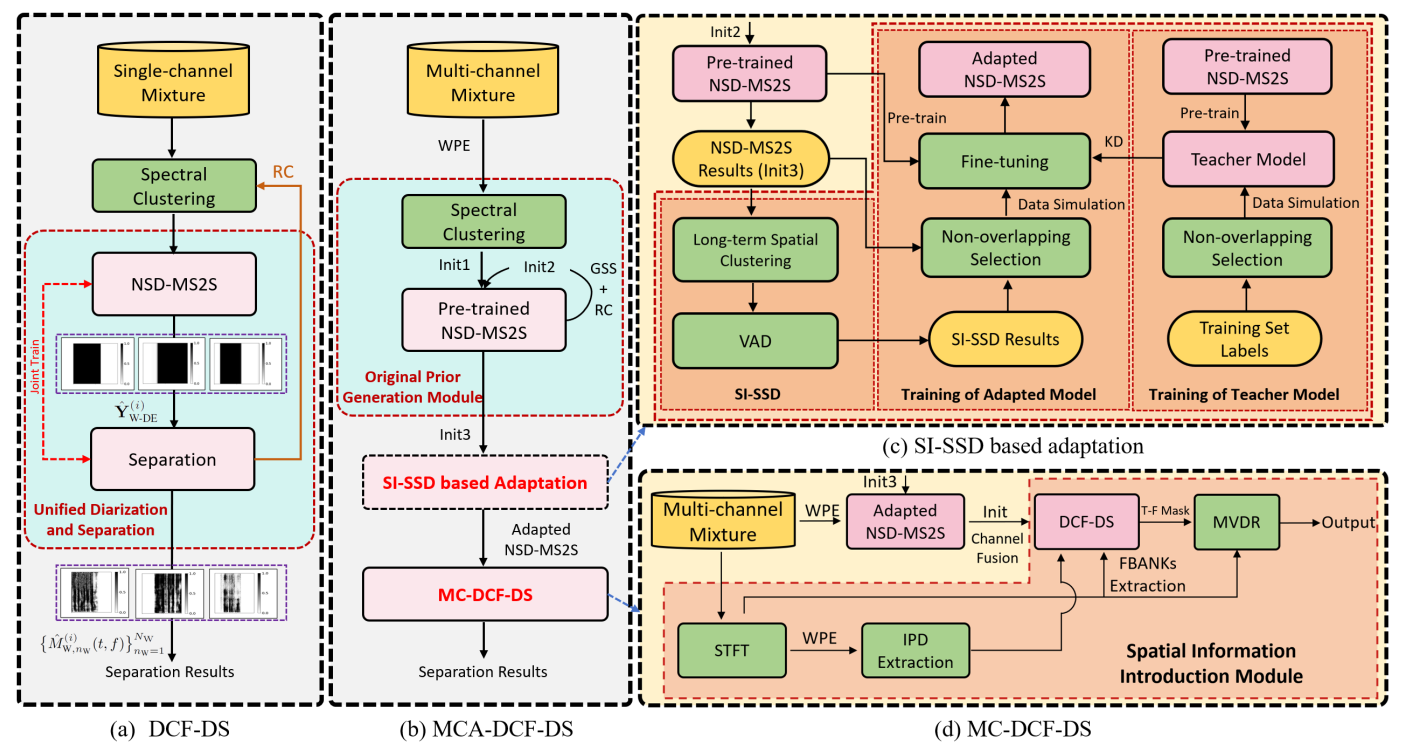
本文聚焦真实多说话人会议场景下的说话人日志、语音分离与语音识别问题。针对原始深度级联融合的日志与分离框架(deep cascade fusion of diarization and separation,DCF-DS)主要依赖频谱信息、在高重叠语音区域性能受限的问题,提出一种多通道自适应深度级联融合日志与分离框架(multi-channel adaptive deep cascade fusion of diarization and separation,MCA-DCF-DS)。该框架在统一建模说话人日志与语音分离的基础上,引入多通道空间信息,以提升复杂会议场景下的语音识别性能。具体而言,在系统层面,MCA-DCF-DS 将单通道 DCF-DS 扩展为多通道深度级联融合日志与分离系统,利用通道间相位差(inter-channel phase difference,IPD)特征和最小方差无失真响应(minimum variance distortionless response,MVDR)波束形成,显式利用麦克风阵列中的空间信息增强语音分离效果。在数据层面,本文采用融合空间信息的基于语音分离的说话人日志系统(spatial information based separation-based speaker diarization,SI-SSD)生成高质量自适应训练数据。该方法通过筛选可靠的单说话人片段并丢弃不可靠的重叠区域,在保留真实空间信息的同时提升自适应数据质量,从而进一步提高自适应模型性能。此外,本文引入知识蒸馏(knowledge distillation,KD)策略,以缓解伪标签带来的漏检问题,使系统在降低漏检错误的同时保持较低的混淆错误。实验结果表明,MCA-DCF-DS 显著优于单通道 DCF-DS 和 CHiME-8 Task 2 官方多通道基线,并在相同语音识别后端下超过 CHiME-8 Task 2 冠军系统,验证了从系统层面和数据层面联合引入空间信息的有效性。
13. EmoInstruct-TTS: Dual-Path Instruction-Guided Emotional Speech Synthesis
论文作者:吴明辉,刘赣俊,方子堃,孟廷,伍宏传,徐冰傲,蔡永龙,陈家胜,杜俊
论文单位:中国科学技术大学,科大讯飞寰语研究院,华为技术有限公司
论文简介:
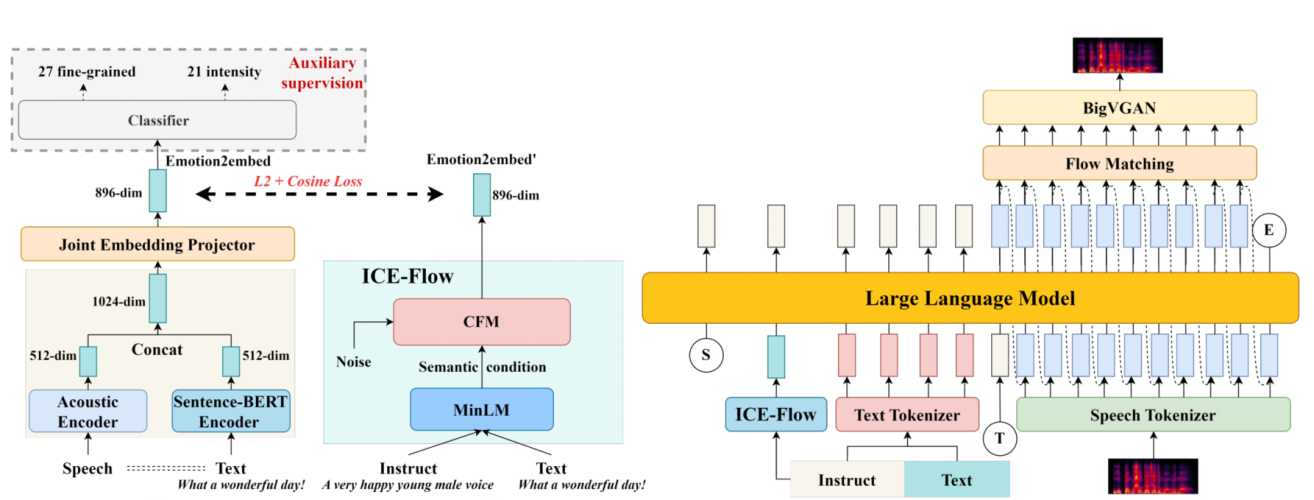
本文聚焦指令引导的情感语音合成这一应用场景,旨在仅凭自然语言指令即可实现对情感类别与情感强度的细粒度可控合成,该技术可广泛应用于虚拟助手、有声读物及对话式智能体等领域。针对现有指令式方法多依赖粗粒度情感标签、缺乏对细粒度强度显式建模这一不足,本文提出一种双路径指令引导模型 EmoInstruct-TTS,该模型可在依据自然语言指令进行语义规划的同时,实现对情感的细粒度显式控制。EmoInstruct-TTS 模型由三大核心模块构成:覆盖 48 种情感状态(27 种细粒度情感类别与由 7 种基本情感、3 个强度等级组合而成的 21 种情感—强度组合)的语义—声学情感表征模块(Emotion2embed)、指令条件情感流模型(instruction-conditioned emotion flow model,ICE-Flow),以及融合语义规划与情感控制的双路径语音合成模块。其工作流程如下:首先,Emotion2embed 通过语义—声学联合编码,将情感语音及其文本描述映射为兼具情感类别与强度有序结构、且与说话人无关的情感表征;随后,ICE-Flow 以自然语言指令为条件,推断出声学对齐的情感嵌入;最终,所推断的情感表征与指令文本一同送入基于大语言模型的合成流程,分别承担情感控制与语义规划,并结合说话人表征语音声码器重构为语音波形。在模型训练阶段,Emotion2embed 采用情感分类、强度分类与有序强度约束相结合的多任务目标进行监督;ICE-Flow 则通过样本级声学对齐与分布级正则化联合优化,以抑制模式坍塌并保留真实情感变化。实验结果表明,相较于 CosyVoice2、CosyVoice3 等强基线模型,EmoInstruct-TTS 在情感可控性与语音自然度上均取得提升,尤其在细粒度情感强度建模方面优势显著。
论文资源:Demo语音网页 https://huanyulab.github.io/EMOINSTRUCT-TTS/
14. Eliminating Stability Hallucinations in LLM-based TTS models via Attention Guidance
论文作者:王诗明,杜志浩,项扬,赵天宇,赵瀚,陈谦,李先刚,郭瀚杰,凌震华
论文单位:中国科学技术大学
论文简介:
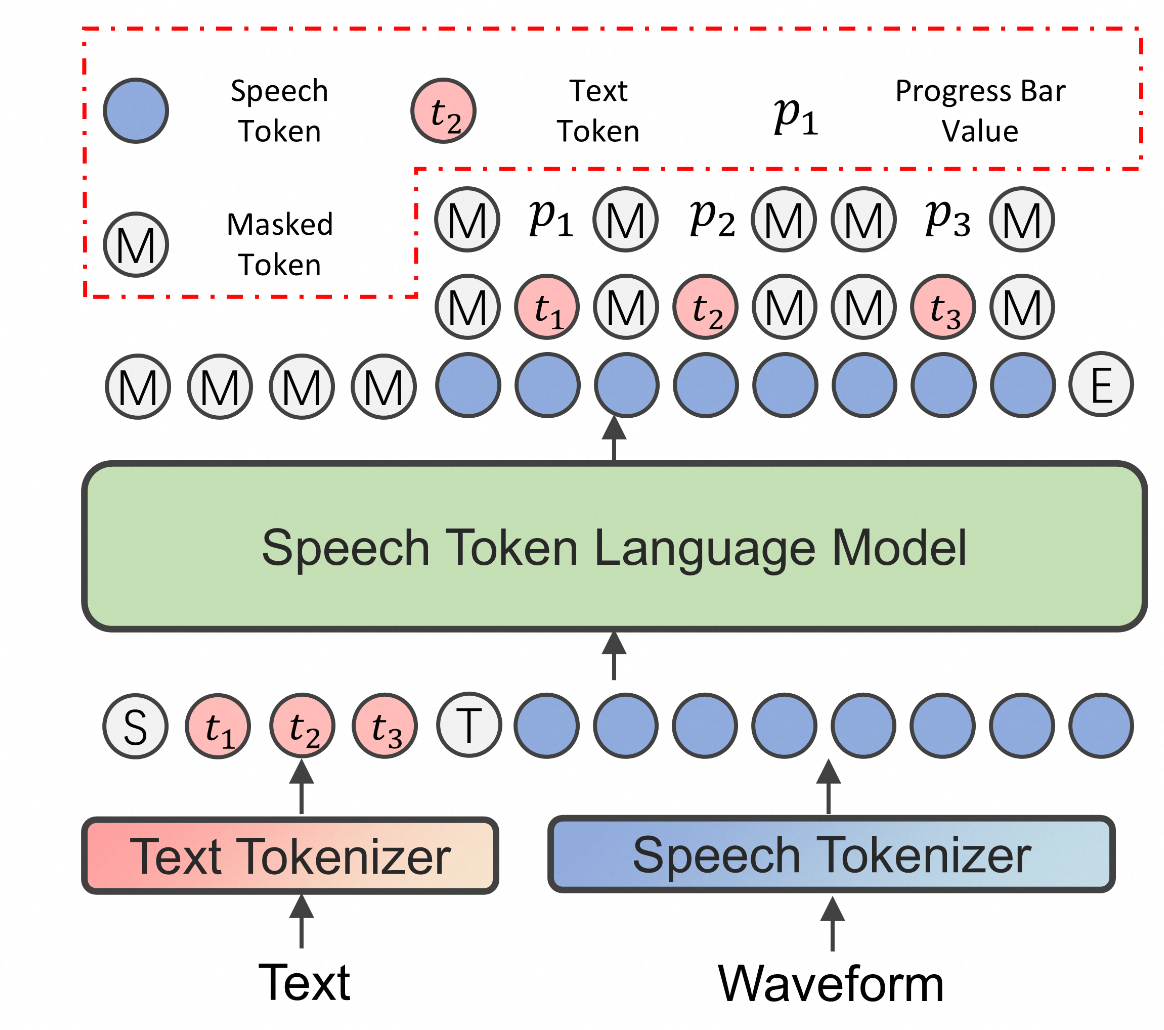
本论文专注于通过改进和利用注意力机制,来解决基于大语言模型(LLM)的文本转语音(TTS)模型中的稳定性幻觉问题(例如语音重复或遗漏)。首先,我们分析了大语言模型中文本标记(text tokens)与语音标记(speech tokens)之间的对齐机制。随后,我们提出了一种名为最优对齐分数”Optimal Alignment Score, OAS)的评估指标,该指标利用维特比算法(Viterbi algorithm)来评估文本与语音之间的对齐质量。随后,我们将 OAS 整合到 CosyVoice2 的训练过程中,以帮助大语言模型学习连续且稳定的对齐。此外,我们利用预训练的注意力值,通过思维链(Chain-of-Thought, CoT)来指导学生模型 CosyVoice2 的训练,从而进一步减少了合成语音中的稳定性幻觉。在 Seed-TTS-Eval 和 CV3-Eval 测试集上的实验结果表明,所提方法能够有效减少 CosyVoice2 的稳定性幻觉,且不会引入额外的负面效应。
论文资源:附录请参阅以下网址:https://wsmzzz.github.io/llm_attn