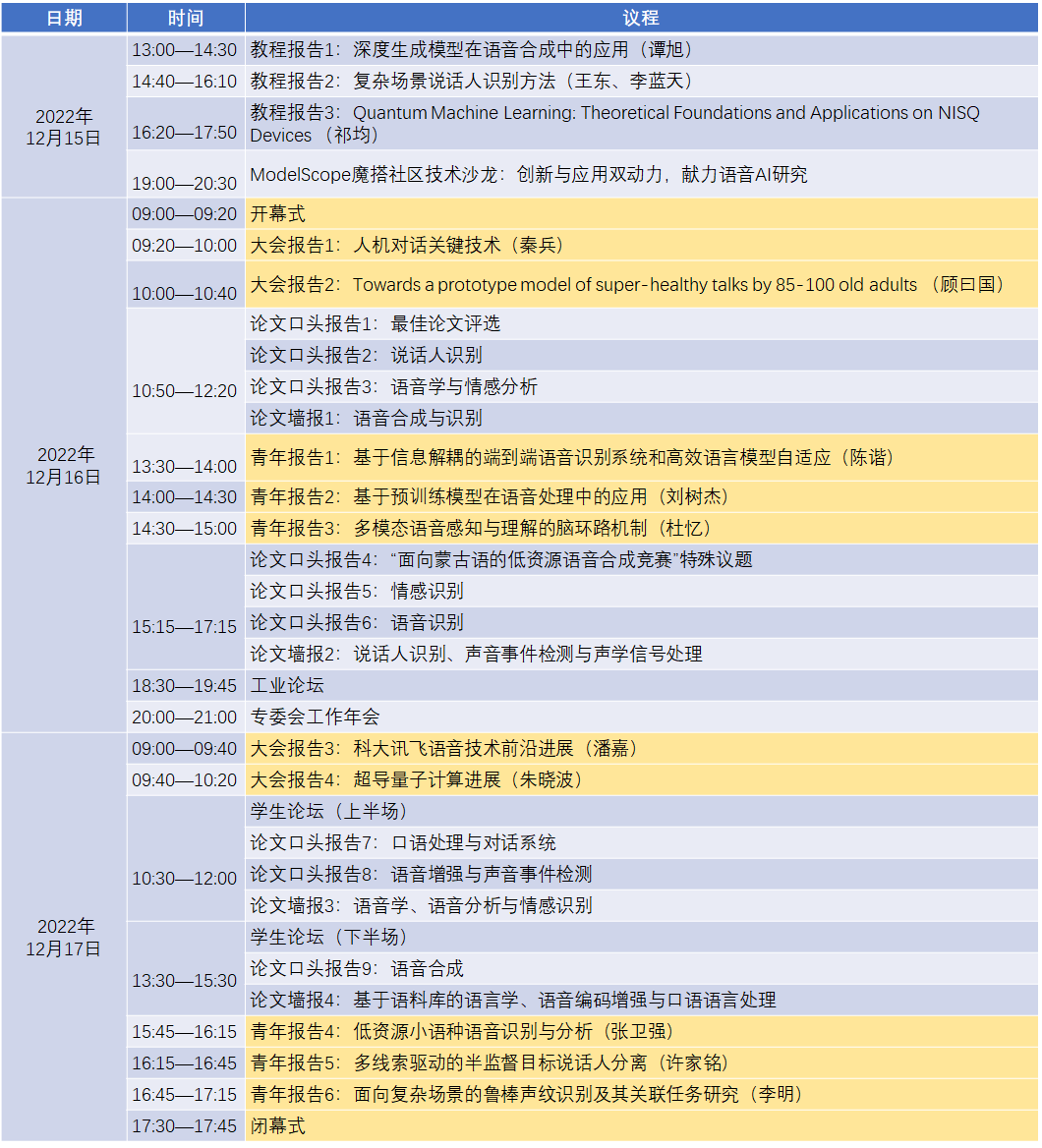
报告嘉宾:秦兵
报告题目:人机对话关键技术
报告摘要:人机对话是人工智能研究的热点之一,受到了学术界和工业界的广泛重视,基于人机对话技术的产品也层出不穷。随着人机对话技术的进展以及人们对于人机对话类产品需求的多样化,使得通用对话系统在适应不同场景、面向不同群体时的能力成为下一阶段人机对话技术和应用的重点发展方向。本报告针对自动回复生成中语言的相关性、一致性、角色化以及情感信息融入等关键技术进行研究,从而进一步提高人机对话的质量及拓宽人机对话的应用场景。
嘉宾简介:秦兵,哈尔滨工业大学计算学部教授,博士生导师,哈尔滨工业大学社会计算与信息检索研究中心主任。国家重点研发课题、国家自然科学基金重点项目负责人。科技部科技创新2030-“新一代人工智能”重大项目管理专家组专家,中国中文信息学会理事/语言与知识计算专委会副主任/情感计算专委会主任。主要研究方向:自然语言处理,知识图谱,情感计算,文本生成。获中文信息学会钱伟长中文信息处理科学技术奖一等奖、黑龙江省科学技术奖一等奖、黑龙江省科学技术奖二等奖和黑龙江省技术发明奖二等奖。入选“2020年度人工智能全球女性及AI 2000最具影响力学者榜单”和“福布斯中国2020科技女性榜”。

报告题目:Towards a prototype model of super-healthy talks by 85-100 old adults报告摘要:This paper presents a preliminary study of talks by 15 speakers, whose ages include 5 over 85s, 7 over 90s, and 3 100s. Talks refer to face-to-face oral interactions between the elders and interviewers. All talks except two are audio-videotaped. These data are part of our project of Multimodal Corpora of Gerontic Discourse (MCGD) funded by the National Social Science Foundation of China (Code 21&ZD294). The expression “prototype model” is adopted as a technical term designating a key concept of our gerontic assessment scheme. Elders aging 60 to 100 are divided into 5-year birth cohorts, and each cohort is assessed in terms of a four-value scale, viz. super-healthy, healthy, normal and abnormal. The super-healthy this paper addresses actually covers three birth cohorts, each of which is treated as super samples against which elders in the same cohort will be assessed according to the four-value scale, hence the term prototype.The oral talks are anatomized in three tiers, viz. the tier of illocution, of emotion and of prosody. The three tier analyses are synchronized in temporal points, and evaluated according to the Principle of Speech-Thought-Emotion-Embodiment Integration (the STEE Principle), as formulated in Gu ( 2013) , 顾曰国(2013, 2018).嘉宾简介:Gu, Yueguo, M.A., Ph.D., Dr. Lit. honoris causa (all from Lancaster University), is presently chief scientist of Artificial Intelligence and Human Language Research Centre. He is also director of China Multilingual Multimodal Corpora and Big Data Research Centre, Beijing Foreign Studies University, and Director of Aging, Language and Care Research Centre, Tongji University/CASS. His research interests include pragmatics, discourse analysis, corpus linguistics, rhetoric and online education. His latest publications include The Routledge Handbook of Pragmatics (co-edited), The Encyclopedia of Chinese Language and Linguistics (co-edited, 5-volumes, Brill), the Chinese Painting, the Chinese Writing by FLTRP, and Gerontolinguistics and Multimodality Studies by Tongji University Press.He was the winner of five national top research prizes, and was awarded a K. C. Wong Fellow of the British Academy in 1997. He is a holder of many honorary posts, most noticeably special professorship of the University of Nottingham, Adjunct Professor of West Sydney University, Visiting Lecture Professor of Peter the Great St. Petersburg Polytechnic University, and Distinguished Research Fellow of Sydney University.

报告摘要:本报告重点围绕语音和音视频预训练、语音识别和语音合成技术的研究热点方向,介绍了科大讯飞的最新技术进展,并对未来的发展进行了展望。嘉宾简介:潘嘉,中国科学技术大学博士,高级工程师,现任科大讯飞杰出科学家。长期从事语音识别、说话人识别、语音合成、深度学习等方向上的前沿技术研究。主导和参与了多个省部级项目,获得安徽省科技进步一等奖、中国电子学会科学技术奖一等奖。带队获得语音识别评测CHiME、多语种识别评测openASR2021、说话人角色分离评测DIHARD3、语音合成评测Blizzard Challenge等国际知名评测任务的冠军。共发表国内外会议期刊论文10余篇,获得授权或公开的发明专利30余项。

报告摘要:由于量子计算在某些问题的处理能力上相比于经典计算机有着压倒性的优势,被普遍认为是下一代的计算技术,因而引起了广泛的关注。超导方案因具有良好的可扩展性就,目前备受关注,各大公司纷纷投资进入该领域。本次报告将主要讲解超导量子计算的现状及近期和中远期目标,并着重介绍我们在超导量子芯片上取得的一系列进展。嘉宾简介:朱晓波,中国科学技术大学教授。主要从事超导量子计算以及超导约瑟夫森结系统的研究。在磁通量子比特与金刚石中的NV色心的量子混合系统上做出了一系列的重要工作。先后创造了超导量子比特最大纠缠数目纪录。研制了超导量子计算原型机“祖冲之号”,实现了“量子优越性”。