

近日,Interspeech 2025会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共15篇论文被会议接收,论文方向涵盖语音识别、语音合成、语音编码、话者识别、语音增强、情感识别、声音事件检测等,各接收论文简介见后文。
Interspeech是由国际语音通信协会(ISCA)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会。本届会议以“Fair and Inclusive Speech Science and Technology”为主题,内容涵盖语音识别、语音合成、语音编码、语音增强、自然语言处理等多个领域。
语音及语言信息处理国家工程实验室于2011年由国家发改委正式批准成立,由中国科学技术大学和科大讯飞股份有限公司联合共建,是我国语音产业界唯一的国家级研究开发平台。2021年底,实验室通过国家发改委的优化整合评估,成功纳入新序列,并转建为语音及语言信息处理国家工程中心。
1. Improving Noise Robustness of LLM-based Zero-shot TTS via Discrete Acoustic Token Denoising
论文作者:鲁叶欣,杜荟鹏,刘飞,艾杨,凌震华
论文单位:中国科学技术大学
论文简介:
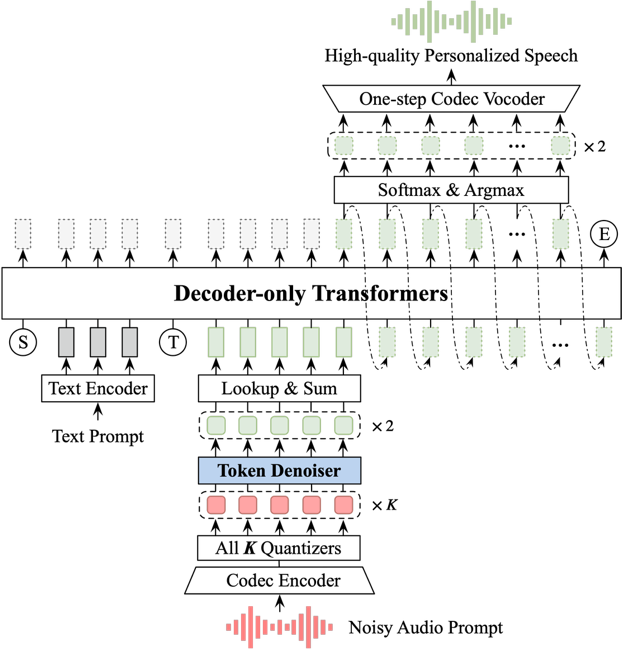
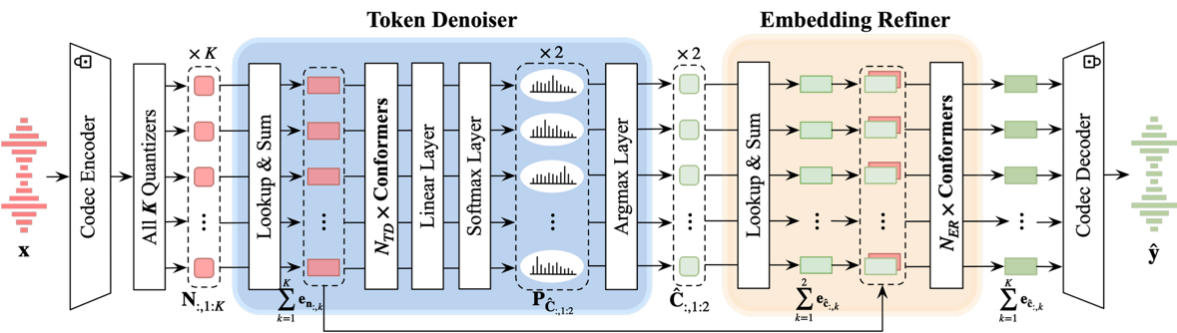
基于大语言模型(large language model, LLM)的零样本语音合成模型往往会保留参考语音中的声学环境特征,因此,当参考语音包含噪声时,合成语音的自然度和可懂度会显著下降。为了解决这一问题,本文提出了一种基于神经编解码器的语音去噪模型,并将其与基于LLM的语音合成模型LauraTTS相结合,实现了噪声鲁棒的零样本语音合成。该去噪模型由音频编解码器、离散声学码去噪模块和声学嵌入精细化模块组成。离散声学码去噪模块首先从带噪语音编码后的离散声学码中预测出前两组干净的离散声学码,这些增强后的离散声学码可作为LauraTTS的声学提示,用于合成高质量的个性化语音;同时,它也可以通过声学嵌入精细化模块与音频编解码器的解码器转换为干净的语音波形。实验结果表明,所提出的编解码器去噪模型在DNS-MOS指标上优于当前最先进的语音增强方法,而所提出的噪声鲁棒的LauraTTS在合成语音的自然度、可懂度和话者相似度方面也优于采用额外语音增强模型对参考语音进行增强的方法,同时仅带来了极小的模型计算复杂度增加。
论文资源:Demo语音网页https://yxlu-0102.github.io/NR-LauraTTS
2. Universal Preference-Score-based Pairwise Speech Quality Assessment
论文作者:施羽飞,艾杨,凌震华
论文单位:中国科学技术大学
论文简介:
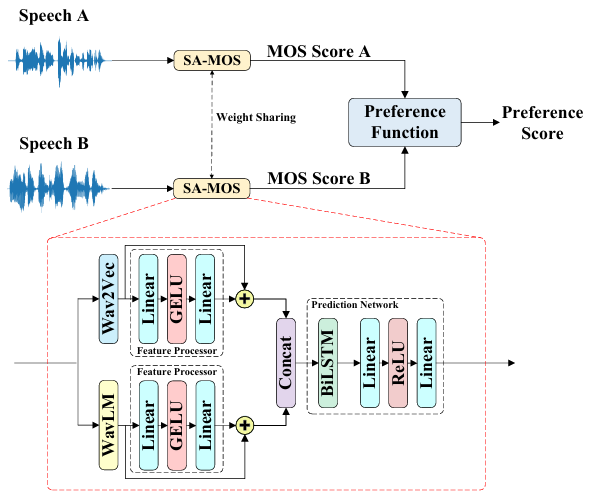
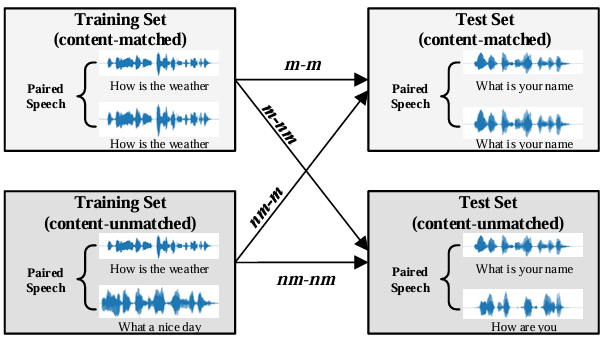
为了比较两个语音生成系统的性能,最有效的方法之一是估计它们生成语音之间的偏好分数。本文提出了一种新的基于通用偏好分数的成对语音质量评估(UPPSQA)模型,旨在预测成对语音样本之间的偏好分数,以确定哪一个具有更好的质量。该模型首先分别预测两个语音样本的绝对平均意见得分(MOS),然后使用偏好函数将它们聚合为相对偏好分数。为了解决偏好数据稀缺的问题,我们还基于 MOS 数据集构建了一个新的成对语音数据集用于实验。实验结果证实,无论是在不同数据类型和标签条件的训练场景中,还是在域内和域外测试场景中,UPPSQA 的预测准确性均优于基线模型,证明了其通用性。
3. Vision-Integrated High-Quality Neural Speech Coding
论文作者:郭姚,艾杨,郑瑞晨,杜荟鹏,江晓航,凌震华
论文单位:中国科学技术大学
论文简介:
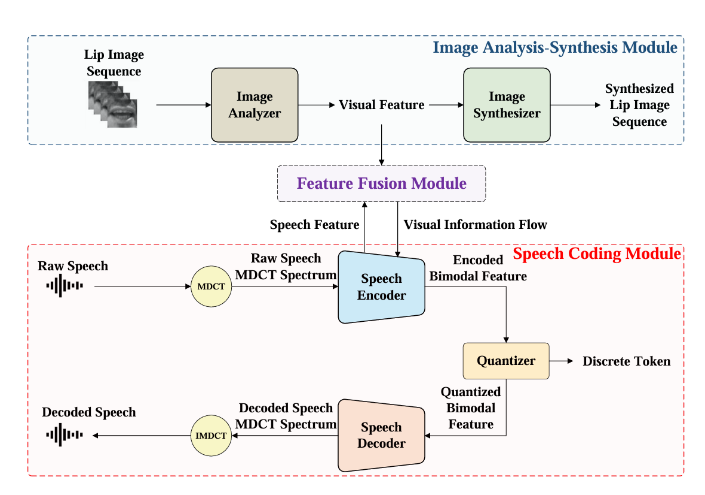
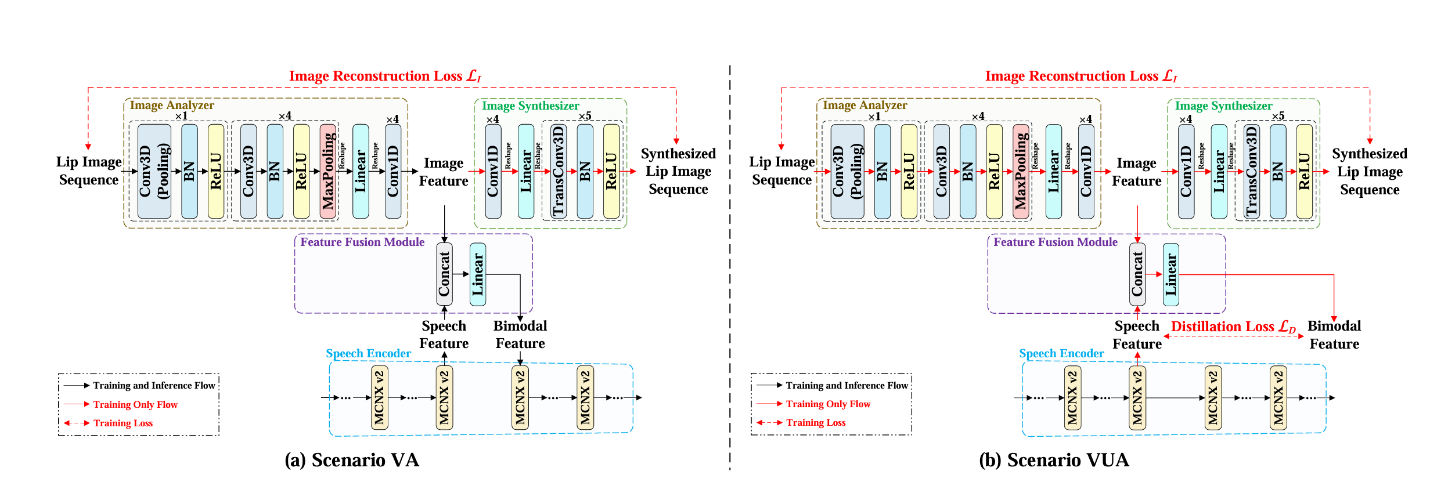
本文提出了一种新的视觉集成神经语音编解码器(VNSC),旨在通过利用视觉模态信息来提高语音编码质量。在VNSC中,图像分析模块从嘴唇图像中提取视觉特征,而特征融合模块则促进图像分析模块和语音编码模块之间的交互,传输视觉信息以辅助语音编码过程。根据在推理阶段是否有视觉信息可用,特征融合模块使用显式集成或隐式蒸馏策略将视觉特征集成到语音编码模块中。实验结果证实,在不增加比特率的情况下,整合视觉信息有效地提高了解码语音的质量,增强了神经语音编解码器的噪声鲁棒性。
论文资源:Demo语音网页https://doge114514-bot.github.io/VNSC_demo/
4. LIST: Language-Independent Speech Token for Multilingual Speech Synthesis with Language Models
论文作者:刘畅,凌震华,顾宇
论文单位:中国科学技术大学,腾讯
论文简介:
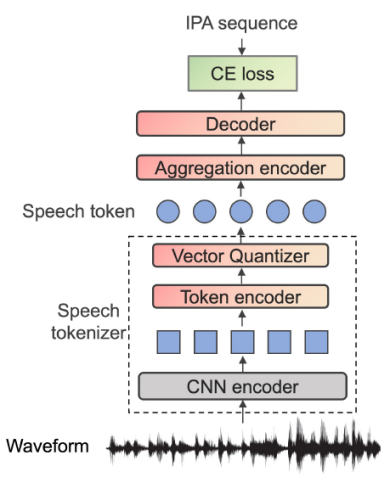
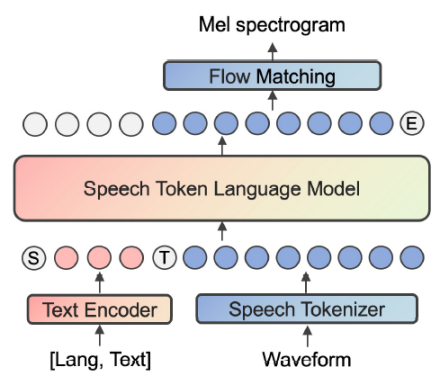
近年来,基于语言模型(language model, LM)的语音合成模型展现出了极高的自然度和强大的零样本合成能力。在这种范式中,离散语音token起着关键作用。先前的研究工作提出利用自动语音识别(automatic speech recognition, ASR)任务来增强语音token中的语义信息并使其与文本更好地对齐。然而,ASR任务中常用的字节对编码(byte-pair encoding, BPE)分词器导致不同语言的文本token集合存在显著差异,这使得挖掘语种共享信息变得困难。本文提出使用国际音标(international phonetic alphabet, IPA)作为ASR模型的训练目标,以学习语种无关的语音token。此外,我们还提出在语音合成模型中使用音色转换器来分离说话人特征。实验结果表明,我们提出的方法在多语言和跨语言零样本语音合成中有效地提高了合成质量、说话人相似度和表现力。
论文资源:Demo语音网页https://ryuclc.github.io/LIST
5. Beyond Manual Transcripts: The Potential of Automated Speech Recognition Errors in Improving Alzheimer’s Disease Detection
论文作者:刘寅龙,冯锐,陈佳鑫,王一鸣,袁家宏,凌震华
论文单位:中国科学技术大学
论文简介:
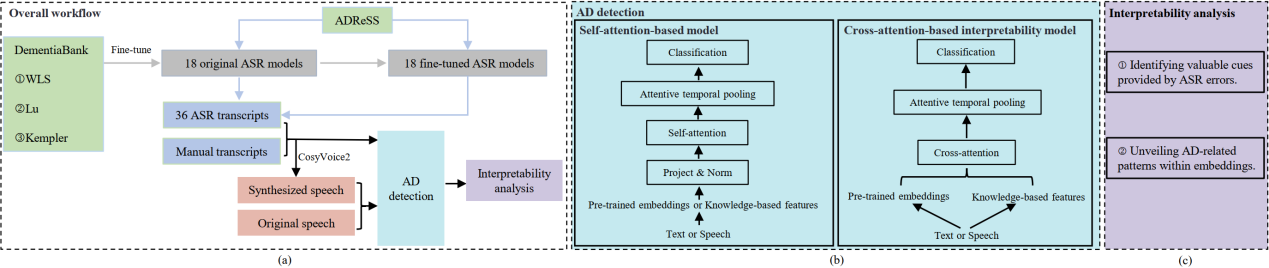
近年来,自动语音识别(ASR)领域的突破性进展使得利用 ASR 转录文本实现阿尔茨海默症(AD)的全自动检测成为可能。然而,ASR 错误对 AD 检测的影响仍未得到充分研究,本文对这一领域进一步探索。我们针对 ADReSS 数据集,使用不同 ASR 模型生成的转录文本及其合成语音开展了 AD 检测的综合性研究。实验结果表明,某些 ASR 转录文本(ASR 转录合成的语音)在检测准确率上优于人工转录文本(人工转录合成的语音),这表明 ASR 错误可能为提升 AD 检测效果提供有价值的线索。此外,我们提出了一种基于交叉注意力的可解释性模型,该模型不仅能够识别这些线索,其性能还优于基线模型或与之相当。我们进一步利用该模型揭示了预训练表征中与 AD 相关的模式。本研究为 ASR 模型在 AD 检测中的应用潜力提供了新的见解。
论文资源:预印版网址:http://arxiv.org/abs/2505.19448
6. Leveraging Cascaded Binary Classification and Multimodal Fusion for Dementia Detection through Spontaneous Speech
论文作者:刘寅龙,李远超,冯锐,何浏,陈佳鑫,王一鸣,陈雨昂,彭彦涵,袁家宏,凌震华
论文单位:中国科学技术大学,爱丁堡大学
论文简介:
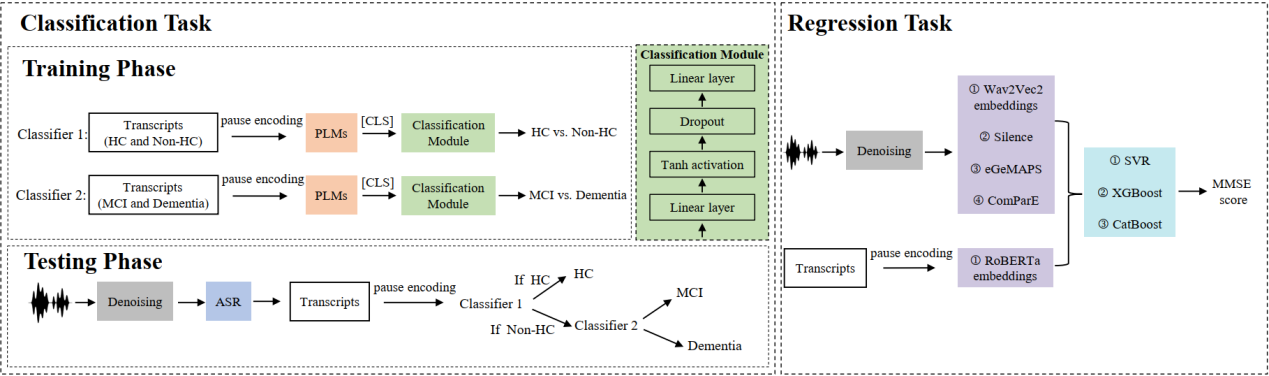
本文介绍了我们提交至2025年PROCESS挑战赛的研究成果,该挑战赛聚焦于用自发性语音进行早期痴呆检测。针对三分类任务(健康、轻度认知障碍、痴呆),我们提出了一种级联二分类框架,通过微调预训练语言模型并融入停顿编码,以更好地捕捉言语不流畅特征。该设计通过重构决策流程简化了多分类问题,并解决了类别不平衡问题。对于简易精神状态检查量表得分回归任务,我们开发了一种增强的多模态融合系统,融合了多样化的声学和语言特征。我们对单个特征集分别训练回归模型,并通过分数平均法应用集成学习。测试集上的实验结果表明,两项任务的表现均优于主办方提供的基线模型,验证了我们方法的鲁棒性和有效性。
论文资源:预印版网址:http://arxiv.org/abs/2505.19446
7. Decoding Speaker-Normalized Pitch from EEG for Mandarin Perception
论文作者:陈佳鑫,王一鸣,张子彧,韩佳洋,刘寅龙,冯锐,梁修媛,凌震华,袁家宏
论文单位:中国科学技术大学
论文简介:
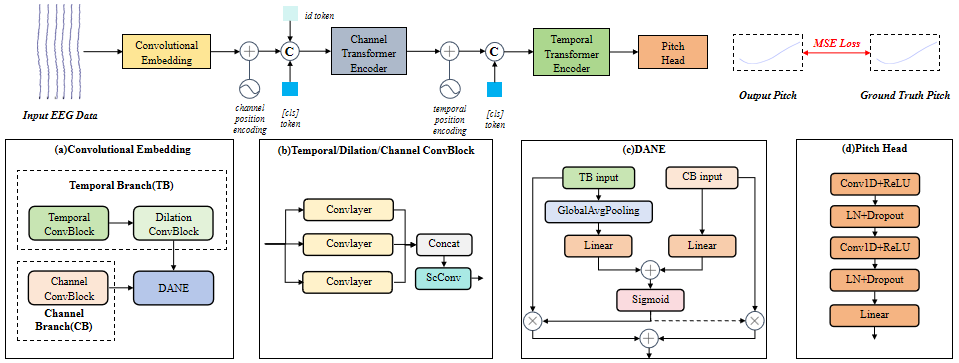
不同说话人产生的相同语音内容在基频轮廓上存在显著差异,但听者的语义感知始终保持稳定。这一现象在以普通话为代表的声调语言中尤为关键,因其声调系统依赖基频变化传递语义。为验证大脑如何处理跨说话人的基频差异,本文构建了一个新的听觉脑电数据集,记录了受试者在听取包含多个说话人普通话单音节语料(含四声调、多样化音素组合)时的脑电图(EEG),并提出EEG解码模型CE-ViViT,可直接从EEG信号中解码原始或说话人归一化的基频轮廓。实验结果表明,该模型能以较低误差实现基频轮廓解码,证实了皮层脑电对语音基频有极强的响应能力。特别值得注意的是,说话人归一化的基频轮廓解码精度显著优于原始基频,进一步表明声调语言(如普通话)在音节层面编码的是说话人归一化的相对基频,而非绝对基频。
论文资源:论文预印版下载地址: https://arxiv.org/abs/2505.19626
8. The Multimodal Information Based Speech Processing (MISP) 2025 Challenge: Audio-Visual Diarization and Recognition
论文作者:高铭,吴世龙,陈航,杜俊,李锦辉,Shinji Watanabe,陈景东,Siniscalchi Sabato Marco,Odette Scharenborg
论文单位:中国科学技术大学,佐治亚理工学院,卡内基梅隆大学,西北工业大学,巴勒莫大学,代尔夫特理工大学
论文简介:
会议场景在语音应用中具有重要价值,但也因其复杂的声学环境而极具挑战。本文总结了在 Interspeech 2025 会议上举办的 MISP 2025 挑战赛的成果。该挑战旨在通过引入视频模态,推动多模态、多设备下的会议转写技术发展。比赛设有三个任务:音频-视觉说话人分离(AVSD)、音频-视觉语音识别(AVSR)以及音频-视觉联合分离与识别(AVDR)。本文介绍了本次挑战的目标、任务设置、数据集、基线系统及参赛队伍提出的解决方案。表现最优的系统在多个任务上相较基线均取得显著提升:最优 AVSD 系统的说话人分离错误率(DER)为 8.09%,相较基线提升 7.43%;最优 AVSR 系统的字错误率(CER)为 9.48%,提升 10.62%;最优 AVDR 系统的最小排列连接字错误率(cpCER)为 11.56%,相较基线提升高达 72.49%。
论文资源:1. https://mispchallenge.github.io/mispchallenge2025/index.html (MISP2025挑战赛官网)
2. https://arxiv.org/abs/2505.13971(论文预印版下载地址)
9. TA-RIR: Topology-Aware Neural Modeling of Acoustic Propagation for Room Impulse Response Synthesis
论文作者:赵骏晖,陈航,王青,杜俊,屠彦辉,马峰
论文单位:中国科学技术大学,科大讯飞
论文简介:
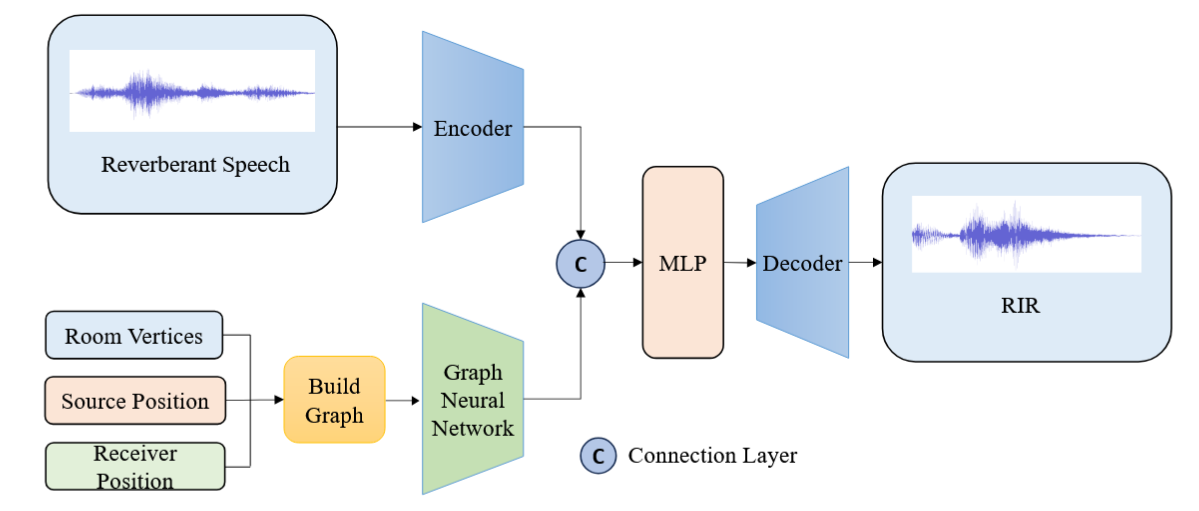
准确估计房间脉冲响应(RIR)对于增强现实和声场建模等应用至关重要。当前方法要么忽略声源与接收点之间的空间关系,要么依赖计算密集的体素网格或全景图像来估计房间脉冲响应。为解决这些挑战,我们提出了TA-RIR——一种拓扑感知神经网络,该网络利用声源和接收点的空间坐标以及混响语音,学习对房间几何结构和声学特性进行编码的紧凑嵌入表示。拓扑感知编码器捕捉空间特征与声学特征之间的结构关系,并通过传播信息解码器进行集成以合成房间脉冲响应。实验结果表明,TA-RIR能够生成高保真的房间脉冲响应,准确保留混响时间等目标声学参数,同时与需要详细三维模型或房间声学特性的方法相比,显著降低了计算复杂度。
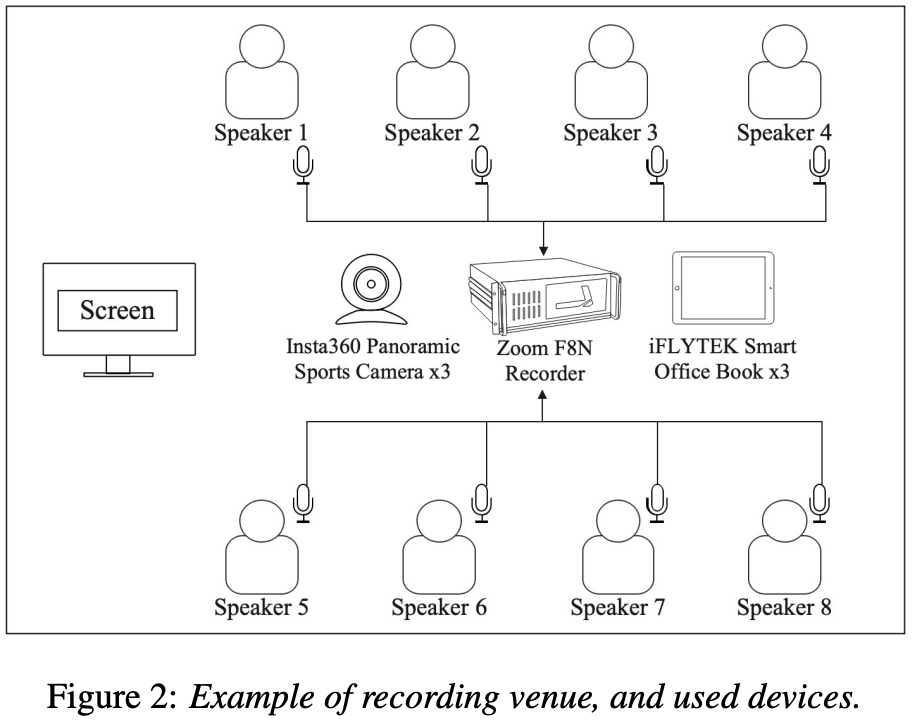
10. A Study of Real-world Audio-Visual Corpus Design and Production: A Perspective from MISP Challenges
论文作者:陈航,杜俊,王青,谢娟,熊世富
论文单位:中国科学技术大学,科大讯飞
论文简介:
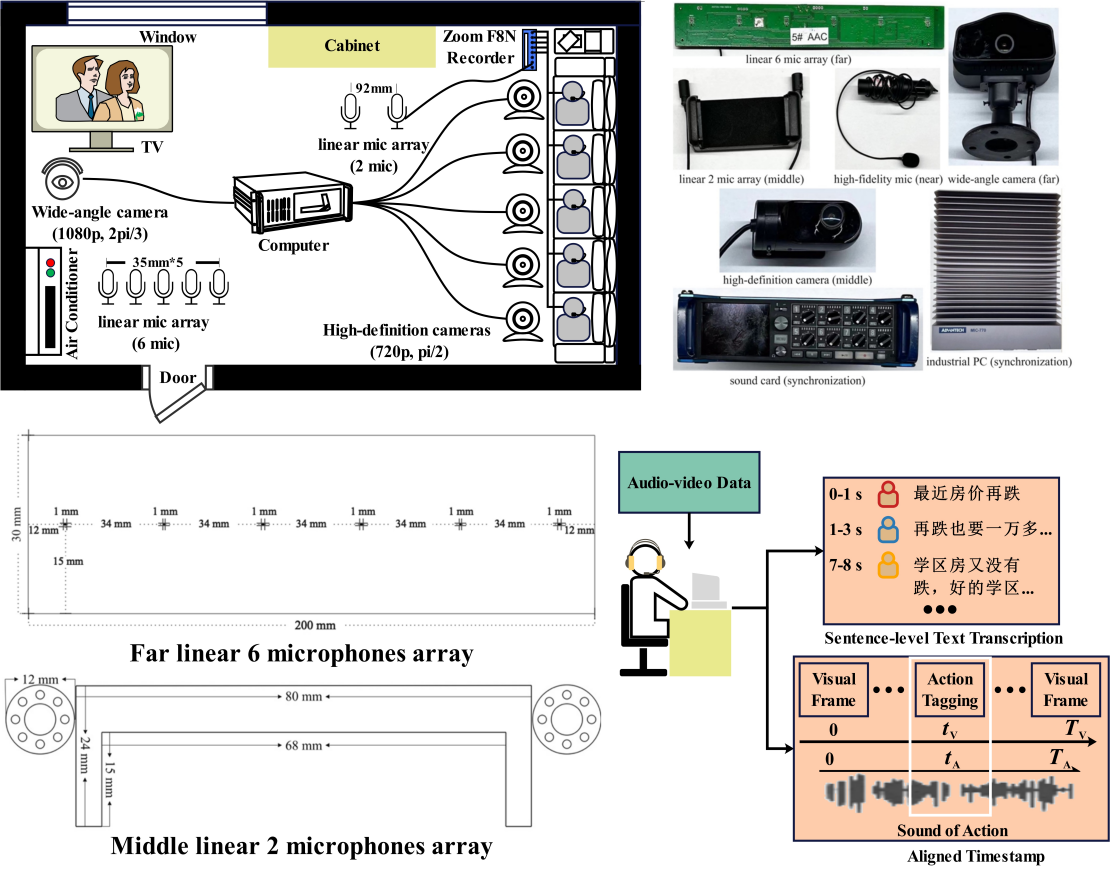
随着语音驱动应用的日益普及,其部署环境中的挑战也日益凸显。为此,视听语音处理 (AVSP) 提出了融合音频和视觉信息以提升多项语音处理任务性能的方案。在此背景下,MISP 挑战赛分别于 2022、2023 和 2024 年 ICASSP 上举办。这些挑战赛发布了视听语料库,以支持四项核心任务:视听唤醒、语音二值化、语音增强和语音识别。这些数据集引起了全球研究界的关注,已有超过 110 个团队下载了该语料库。本文从场景选择、录音设备和流程以及人工转录和对齐等多个角度对 MISP 语料库的设计进行了全面分析,突出了其优势和局限性,并为未来 AVSP 语料库的设计提供了见解和建议。
11. Parameter-Efficient Fine-tuning with Instance-Aware Prompt and Parallel Adapters for Speaker Verification
论文作者:彭圣宇,郭武,张结,管煜,戴礼鹏,李作亮
论文单位:中国科学技术大学
论文简介:
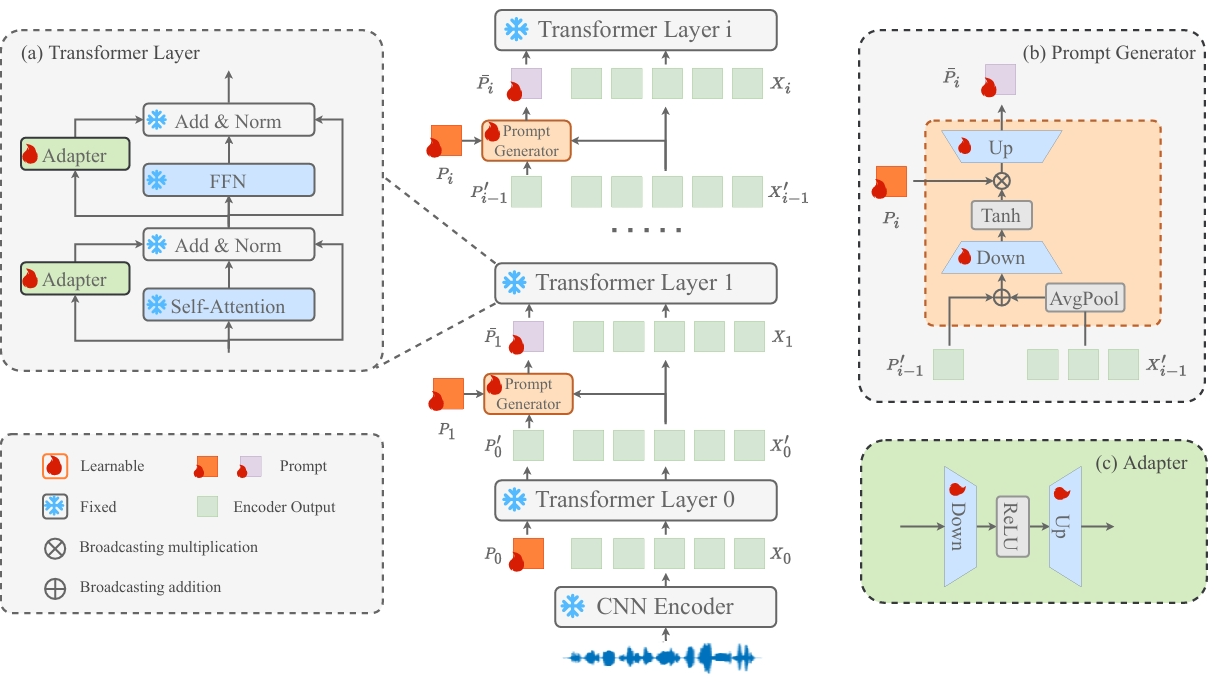
在本文中,我们提出了一种参数高效的微调方法(PEFT),用于预训练模型适应说话人验证任务。该方法在统一框架下同时引入了 Adapter 微调 和 Prompt 微调两种微调方法。不同于传统的静态 prompt,我们在预训练模型的相邻 Transformer 层之间插入了一个 prompt 生成器,该模块能够结合话语级的话说人表征,动态生成具备实例感知能力的 prompt。与此同时,我们还在每个 Transformer 层的多头注意力机制(MHSA)与前馈网络(FFN)中并联的插入了 adapter 分支,以更有效地建模说话人相关信息。在 VoxCeleb 数据集上的实验结果表明,在仅更新少于 10% 参数的情况下,该方法依然表现出优越的性能。
12. Leveraging Multi-Level Features of ATST with Conformer-Based Dual-Branch Network for Sound Event Detection
论文作者:戴礼鹏,王青,张结,彭圣宇,管煜,郭武
论文单位:中国科学技术大学
论文简介:
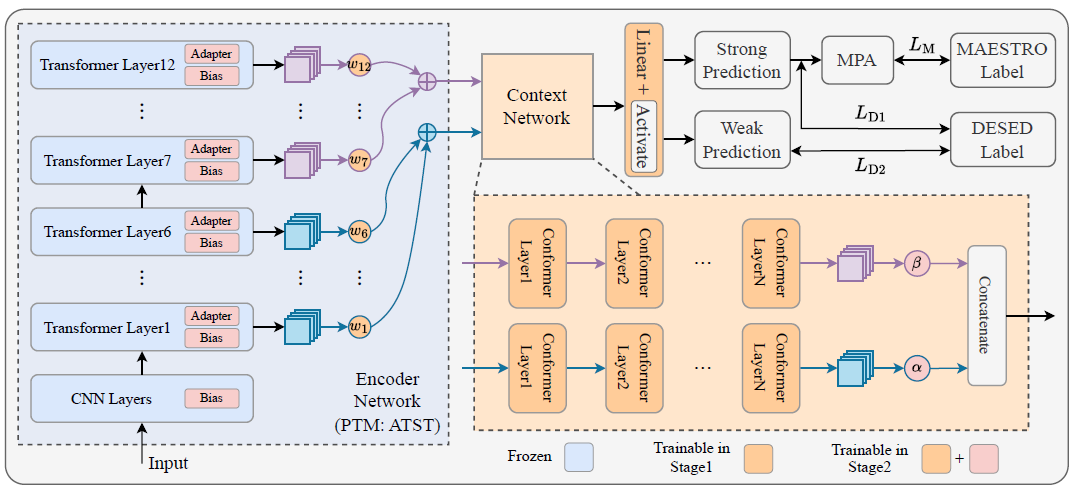
在本文中,我们提出了一种基于Conformer的双分支框架,用于充分利用预训练模型(PTM)中的多层特征,以提升声音事件检测(SED)性能。该框架遵循主流结构,由前端编码器(基于预训练的Audio Teacher-Student Transformer,ATST)和后端上下文网络组成。前端将ATST的Transformer层平均划分为浅层与深层两个部分,并通过加权融合策略有效整合多层特征;后端则采用双分支Conformer,从融合后的特征中提取高级和低级线索。此外,为降低训练参数量,模型训练阶段引入Adapter微调方式,避免对ATST的全量微调,在参数显著减少的情况下仍可获得可比的性能。在DCASE 2024挑战赛任务4的验证集上,实验结果证明了所提出方法的有效性。
13. Finetune Large Pre-Trained Model Based on Frequency-Wise Multi-Query Attention Pooling for Anomalous Sound Detection
论文作者:江南、宋彦、顾庆、宋皓宇、戴礼荣、Ian McLoughlin
论文单位:中国科学技术大学、新加坡理工大学
论文简介:
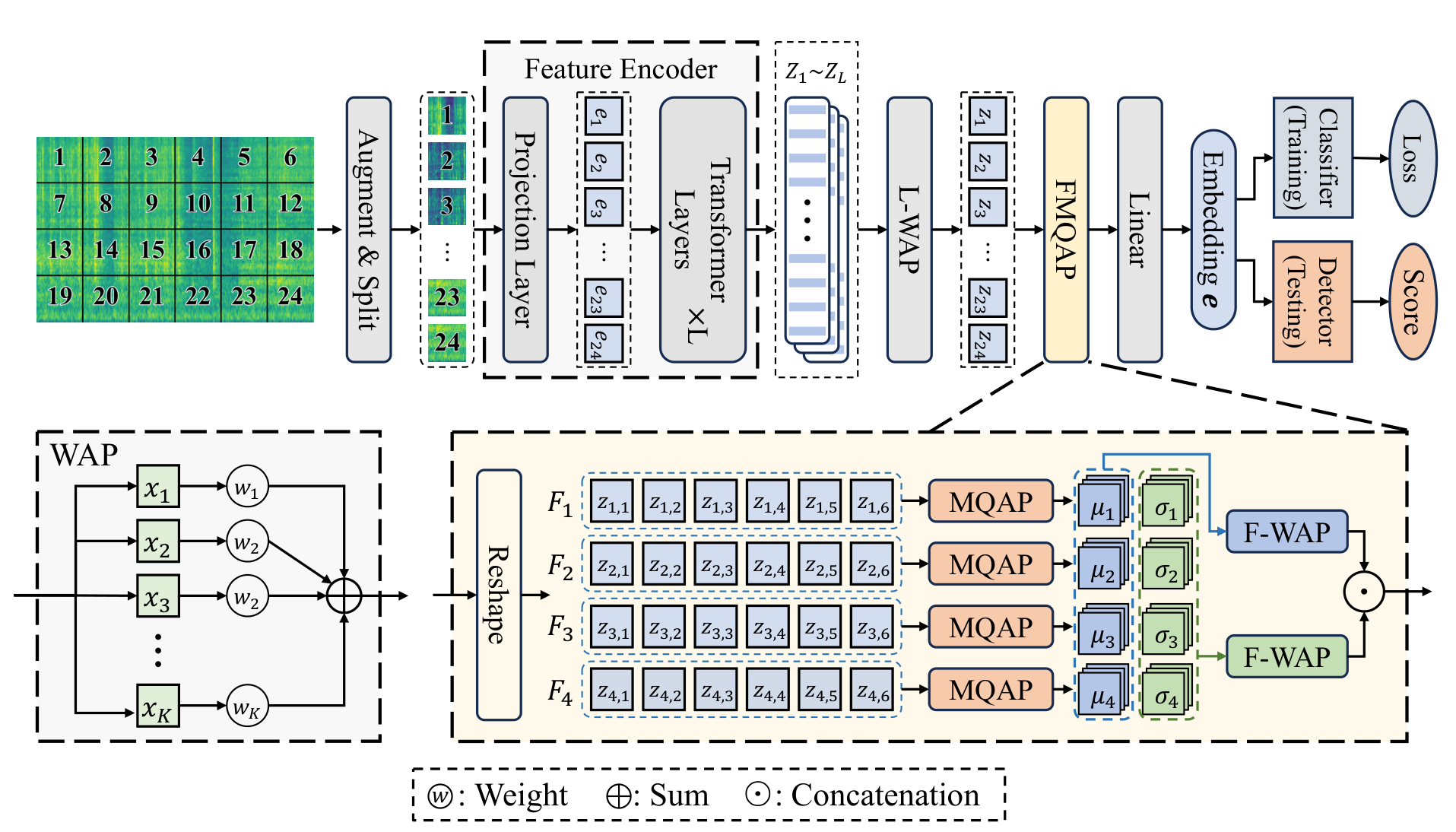
现有的异常声音检测(Anomalous Sound Detection, ASD)方法通常依赖于对正常声音的建模,通过生成式或判别式方式识别音频中的偏差,将其判定为异常。在生成式方法中,模型尝试重构输入声音,重建误差被用作异常指标;而判别式方法则通常使用分类器区分不同类型的声音或检测是否偏离正常分布。然而,由于异常事件本身在实际数据中出现频率极低且表现形式多样,导致这些方法在面对未知或未见的机器类型时,泛化能力较弱,容易将未见的正常声音误判为异常,或无法识别真正的异常。为了解决这一问题,本文提出了一种基于频率级多查询注意力池化(Frequency-wise Multi-Query Attention Pooling, FMQAP)的方法,结合了大型预训练模型的强大表征能力与针对音频时频特征的细粒度建模策略。FMQAP 的核心思想是利用来自预训练音频模型(如 BEATs)多个 Transformer 层的输出,通过层级加权平均融合不同层级的信息,并引入多查询注意力机制,在频率维度上对音频特征进行精细建模。这种机制可以有效捕捉不同机器类型在频率分布上的特征差异,从而增强模型在首次遇到新机器时的识别能力。在实际评估中,本文方法在 DCASE 2023 Task 2 的基准测试上表现出色,获得了 77.62% 的官方得分,显著超过现有的最先进方法。这一成果表明,结合大规模预训练模型与频率感知注意力机制,可以在解决 ASD 泛化性难题方面发挥关键作用。FMQAP 不仅提升了模型在数据稀缺环境下的鲁棒性,也为工业智能监测系统提供了更加可靠的技术方案。
14. An Effective Anomalous Sound Detection Method Based on Global and Local Attribute Mining
论文作者:江南、宋彦、顾庆、宋皓宇、戴礼荣、Ian McLoughlin
论文单位:中国科学技术大学、新加坡理工大学
论文简介:
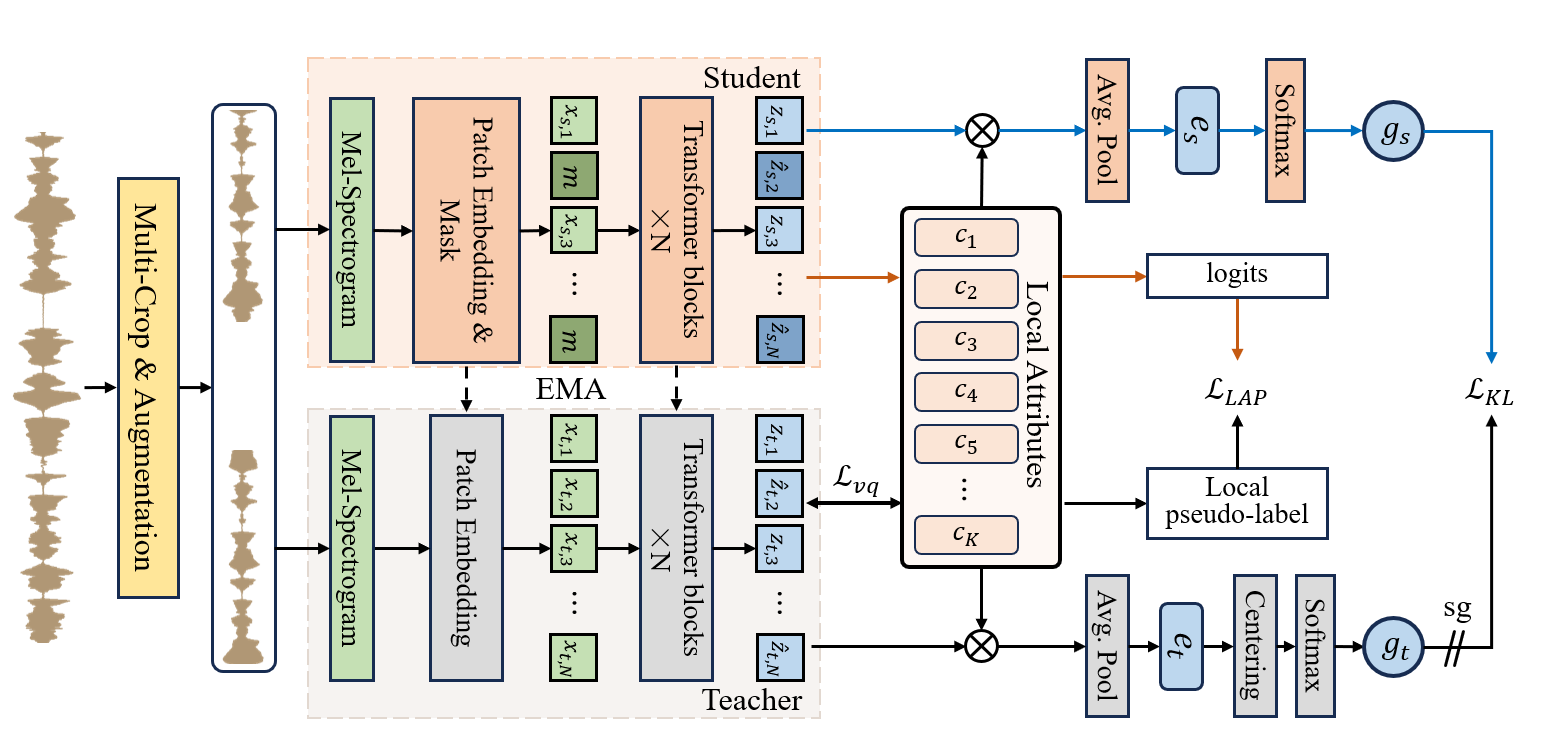
近年来,异常声音检测(Anomalous Sound Detection, ASD)领域取得了显著进展,尤其是利用属性信息(如机器类型、工作状态等)进行建模的方法,在多个基准任务中表现优异。然而,在实际工业场景中,源域和目标域之间往往存在明显的差异,如机器运行状态、环境噪声、录音条件等不一致,这种域偏移和属性不平衡的问题仍是当前 ASD 面临的核心挑战之一。为此,本文提出了一种创新的全局与局部属性联合挖掘方法——GLAM-ASD(Global and Local Attribute Mining),旨在在无监督设定下有效提升模型的跨域泛化能力。该方法构建了一个双分支Transformer编码器结构,分别由教师分支与学生分支组成。学生分支采用掩码块重建策略,以建模音频序列的上下文关系,从中提取时序结构和潜在语义。教师分支则通过指数移动平均机制,从学生分支中动态获取参数,用于稳定生成目标表示。在训练过程中,GLAM-ASD首先从音频中无监督地提取全局属性和局部属性。随后,学生分支不仅通过全局自蒸馏机制学习教师分支的高质量表示,还基于所挖掘的局部属性生成伪标签,引导模型对更细粒度的特征进行学习。在DCASE 2023 Task 2基准测试中的实验结果表明,GLAM-ASD在多个机器类型下均表现出色,尤其在目标域上的性能显著优于现有方法,验证了其在提高模型跨域鲁棒性方面的潜力和有效性。
15. A Domain Robust Pre-Training Method with Local Prototypes for Speaker Verification
论文作者:顾庆,宋彦,宋皓宇,江南,戴礼荣,Ian McLoughlin
论文单位:中国科学技术大学,新加坡理工大学
论文简介:
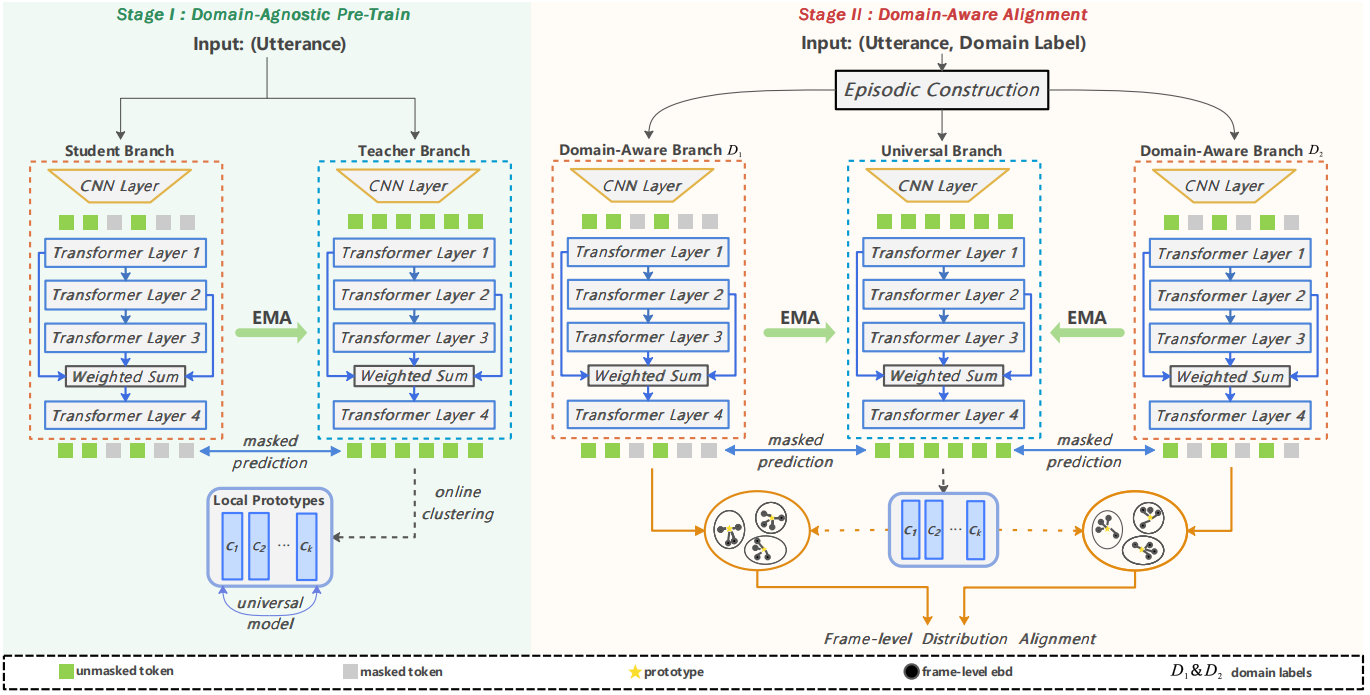
现有的自监督说话人验证(Speaker Verification, SV)方法通过在大规模无标注语音数据上训练,在说话人表征学习方面展现出显著性能。然而,大多数自监督学习方法依赖于话语级别的对比学习或自蒸馏机制,在应对由不同语言和风格所引起的域偏移问题时仍存在一定的局限性。为此,本文提出了一种面向说话人验证的两阶段域鲁棒预训练方法,重点是通过结合局部原型引导帧级域相关信息消除。具体而言,我们采用了一个基于 Transformer 架构的编码器,并在其基础上构建用于局部特征学习的自蒸馏框架:首先,进行与域无关的预训练,通过在线聚类生成局部原型;随后,结合基于域间分布对齐的情景学习范式,引导模型学习具备域泛化性的局部特征。为评估所提域鲁棒预训练方法对说话人验证任务的提升效果,我们分别在 CNCeleb 和 VoxCeleb 基准数据集上进行了话语级别监督下的微调实验,验证了本方法的有效性。