
继2020年、2022-2024年在国际声学场景和事件检测及分类挑战赛(Challenge on Detection and Classification of Acoustic Scenes and Events,简称DCASE)获得冠军后,今年,中科大语音及语言信息处理国家工程研究中心杜俊教授、王青副研究员带领团队联合科大讯飞研究院、国家智能语音创新中心(以下简称“USTC-NERCSLIP联合团队”)获得声音事件定位与检测任务音频和音视频双赛道第一;同时,USTC-NERCSLIP团队还联合中国矿业大学智能信息处理团队获得机器声纹无监督异常检测任务第一。
作为目前声音事件领域最权威的竞赛,DCASE自2013年组织发起已举办了11届。今年,DCASE 2025挑战赛共设置了6个任务,吸引了全球86支队伍进行角逐,接收了277个提交系统。
声音事件定位与检测任务采用了真实场景下的立体声数据,除了需要估计声源的到达方向和距离,在音视频赛道上还需要预测声源是否在拍摄画面内,任务难度显著提升。

USTC-NERCSLIP联合团队人员
音频赛道:立体声通道交换和独立训练-联合推理方法解决多任务问题
本次声音事件定位与检测任务(Task 3)的测试数据采用了真实场景下的立体声,为参赛团队带来了很大挑战;此外在实际场景中,不同类别声音事件的时域重叠率较高,也增加了声音事件的分离与识别难度。
参赛团队需要在复杂的声音环境中,准确地预测声音事件的类别,同时估计声源到达方向和声源距离。这是一场多任务建模的“硬仗”,对算法的精准度和鲁棒性提出了极高的要求。
为应对立体声训练数据量有限的问题,基于在DCASE 2024 同类任务中夺冠的音频通道交换数据增强方法,联合团队进一步提出了立体声通道交换(Stereo Channel Swap,SCS),有效扩充了训练数据集,提升了模型的泛化能力和鲁棒性。
此外,联合团队采用了独立训练-联合推理方法解决多任务的技术方案。具体来说,联合团队训练的三个子系统分别专注于解决声音事件类别-声源坐标估计,声音事件类别-DOA估计和声音事件类别-声源距离估计,并在推理阶段联合三个子系统得到最终多任务的预测结果。
Task3音频赛道联合团队提出独立训练和联合推理的方法
联合团队所提出数据增强方法和独立训练-联合推理方法有效地解决多任务问题,在三个子任务上表现出色。最终,联合团队在检测F-score、定位错误率和相对距离误差三项指标中全部获得第一,其中F-score超越第二名绝对值3.6%,最终以显著优势获得单音频赛道冠军。
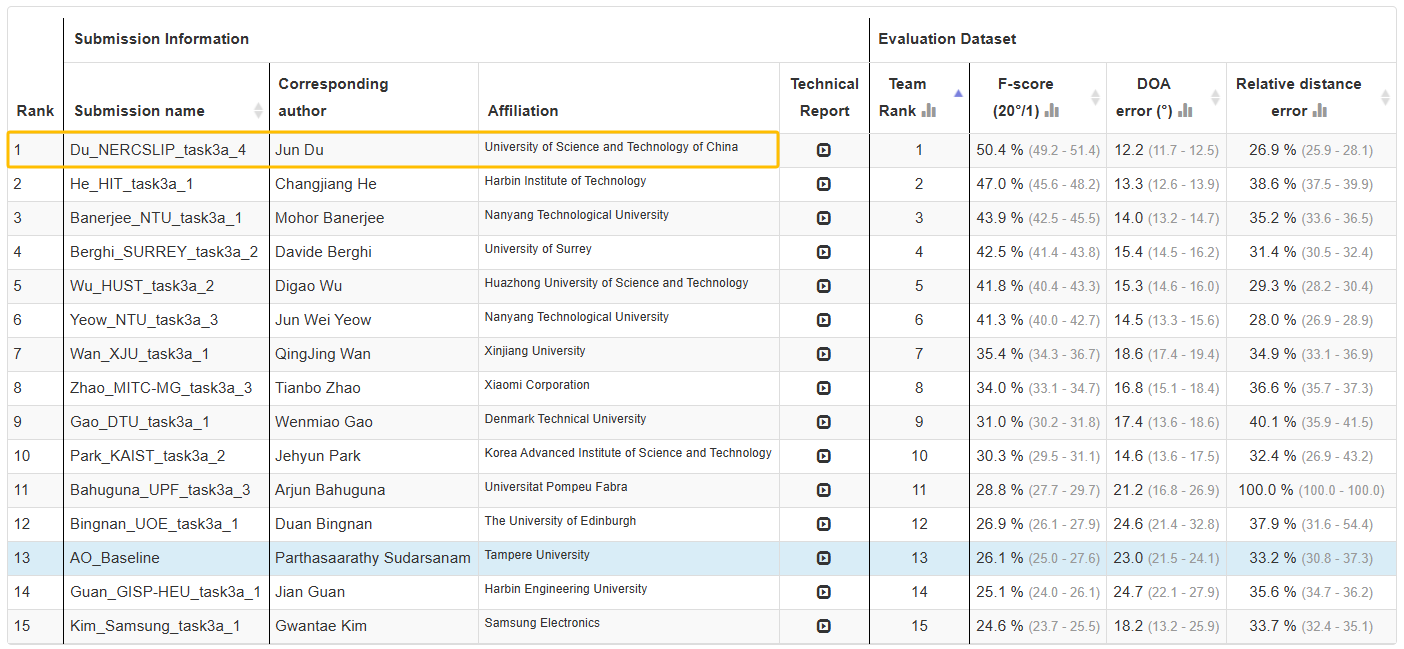
联合团队在Task 3音频赛道中夺冠
与之前采用全景图作为视频模态输入不同,此次音视频赛道采用从全景图中随机截取固定角度的图像,视角与真实拍摄模式更接近,以这类视频数据作为训练测试数据。但这种方式下,发声源可能会出现在视频画面之外,因此比赛还要求预测发声源是否在画面里,预测准确性也参与计算最终评测指标,这对于音视频算法提出了更高的要求。

左图为之前的全景图,黄色和蓝色发声源都在画面内;右图为此次比赛视频数据的画面视角,可以看到此前黄色的发声源不在画面当中。
针对这一挑战,联合团队提出了多项创新技术,通过视听像素交换、跨模态知识迁移、视觉后处理等方法,有效提升了模型对真实场景下音视频声音事件的定位与检测能力:
视听数据增强:使用视听像素交换(AVPS)方法丰富了训练数据多样性,通过视频帧水平翻转模拟视角变换,同时保持左右声道与画面的空间对应关系,显著提升了模型泛化能力。
知识迁移与视觉后处理:通过跨模态迁移学习技术,利用教师模型提取音频时空特征,指导学生模型聚焦与声源相关的视觉区域,加快了模型在音视频任务的学习速度,新增轻量级分类器预测声源是否位于屏幕内,同时采用人体关键点检测修正角度预测偏差,并结合声源类别目标检测(Grounding DINO)进行后处理优化,实现了高精确的声源定位。
通过上述方案,联合团队最终在音视频赛道的F-score上取得41.6%的成绩, 以超越第二名绝对值6.8%的大幅优势获得冠军,实现了全新突破。
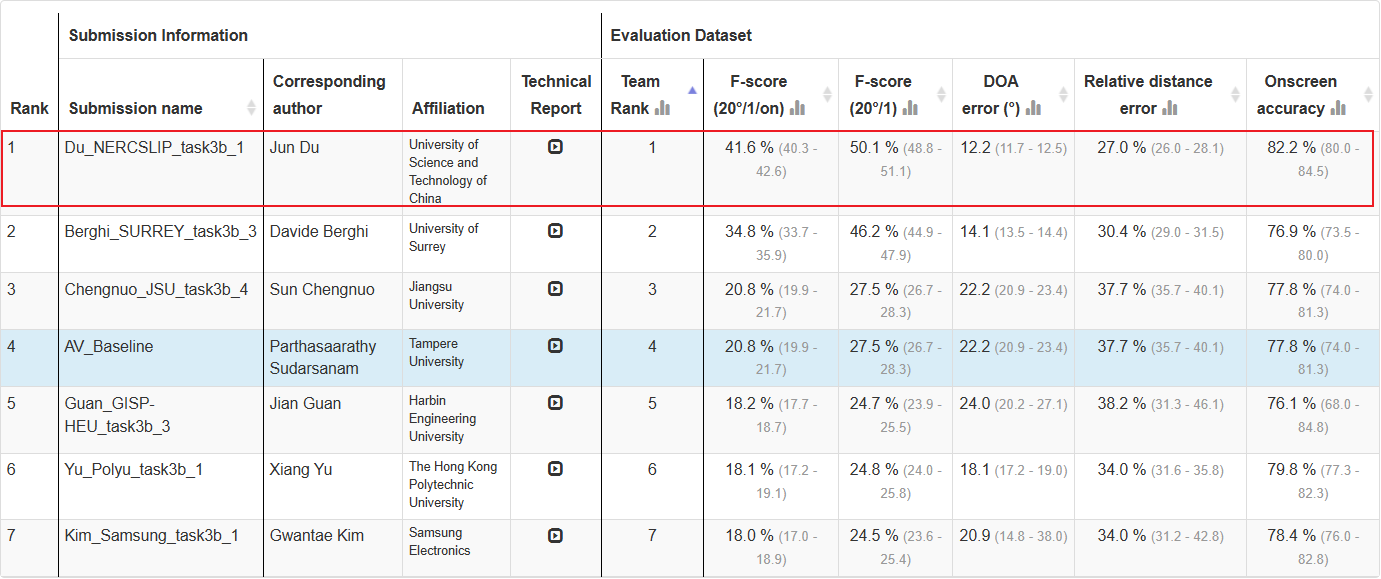
联合团队在Task 3音视频赛道中夺冠
机器声纹无监督异常检测任务有35支队伍参赛,数量为历年之最,强手如云。这一任务要求参赛团队根据机器运行时采集的音频数据,判断机器是否处于正常运行状态,即“异音检测”。此外,今年该任务还提供了干净机器音和纯噪声的附加数据,对结合附加数据的方案设计提出了新挑战。

USTC-NERCSLIP联合团队人员
解析机器声纹异常特征:基于声音分离与领域增强预训练的机器属性分类方案
机器声纹无监督异常检测任务(Task 2)中,需要根据机器运行时的声音来检测机器运行状态是否正常。
主办方仅提供机器正常运行状态的声音数据用于训练异音检测模型,这些数据来自多种类型的机器,包含域标签(源域或目标域)以及属性标签(如型号、速度、档位等)。
其中一部分类型机器声音数据作为开发集(Development dataset),并提供验证数据,用来验证方案有效性;另一部分类型机器的数据则作为额外训练集(Additional training dataset)与最终测试集(Evaluation dataset),但不提供验证数据。
此外,今年每种机器都提供了附加集合(Supplemental),包括干净机器音或纯噪声数据,可用于数据降噪、数据增强等前处理操作。
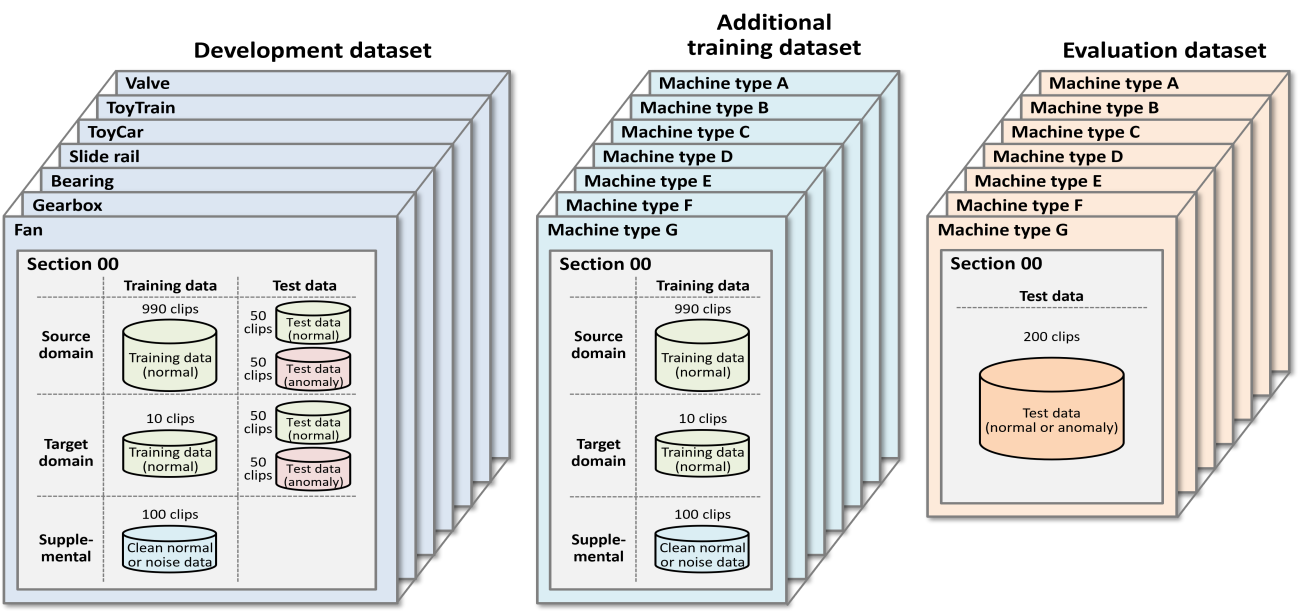
Task 2 数据集情况
此次任务数据的构成,带来了以下难点:
额外训练集中机器缺乏带正常、异常标签的验证集,无法根据验证集结果进行针对性模型调优;而开发集中机器虽提供验证集,但其与额外训练集中机器数据分布差异巨大,根据该验证集选择的方案在最终测试集上的效果并不是最佳。因此,该任务对模型的泛化性和鲁棒性提出了极高的要求。
今年比赛一部分机器提供少量干净机器音数据,另一部分机器则提供纯噪声数据,看似扩充了可用数据,但是缺乏加噪前后的样本对,难以直接应用传统声音分离方案。相较于语音分离降噪任务,机器声音分布与噪声分布区分性更低,声音分离难度更高。
针对以上难点和挑战,联合团队提出了基于自研声纹预训练底座+领域增强预训练技术,结合声音分离数据增广的属性分类微调方案:
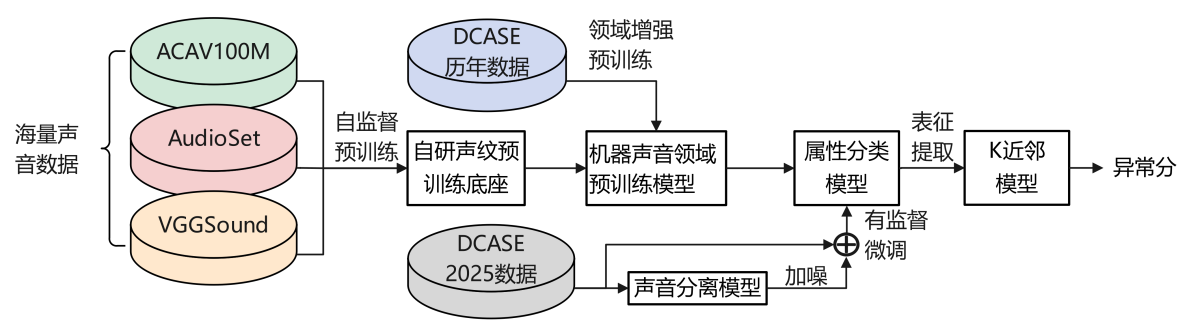
整体方案流程图
自研声纹预训练底座:采用 9 万小时的海量开源声音数据集,进行声纹预训练模型底座的自监督预训练。通过构建师生双分支自蒸馏网络,创新性设计时频域均衡特征,增强模型对各类声音的处理能力。通过构建段级与帧级双粒度训练目标,增强通用声音特征学习能力,推动模型实现全局语义与局部细节特征的协同捕捉。此外,团队还创新性的加入数据增广策略以及全局对比损失,进一步增强了全局语义信息的提取能力。
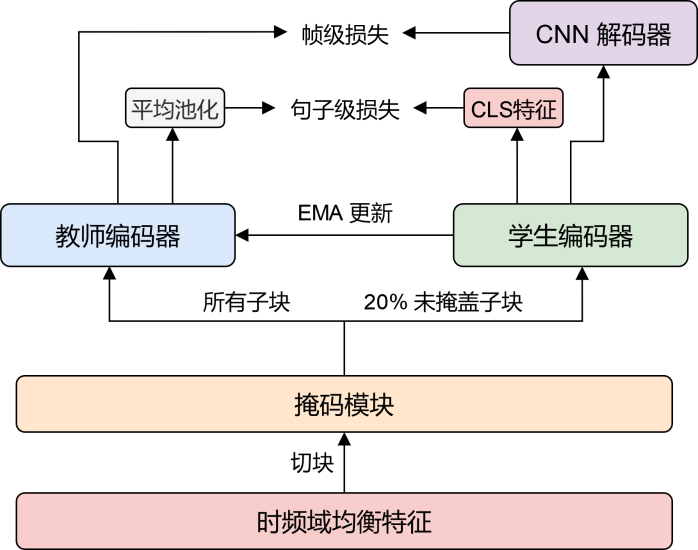
自研声纹预训练模型流程图
领域增强预训练:在自研声纹预训练模型底座基础上,采用历年该任务数据集,并针对不同机器声学特征差异,定制化设计专属掩码策略,对模型做进一步的机器声音领域增强预训练。该策略帮助模型将已学习到的通用声音知识迁移到特定机器声音领域中,使模型能够在微调时更好地适应机器声音建模的下游任务。
声音分离数据增广:采用主办方提供的纯噪声以及样本中抽取的噪声段,构建噪声数据集,并以此构造出大量干净机器音、纯噪声与带噪机器音的三元组,指导声音分离模型训练。将原始训练数据通过分离模型,生成干净机器音数据,并使用噪声数据集对分离后的数据进行加噪,生成大量带噪机器音数据,丰富了后续属性分类模型训练数据的多样性,有效提升了模型在不同工况下的泛化性及鲁棒性。
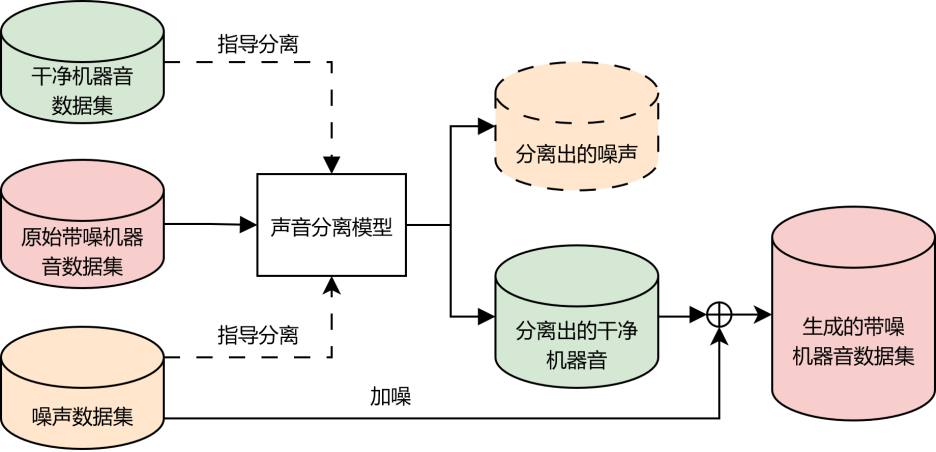
声音分离数据增广流程图
属性分类微调:将原始训练数据以及增广后的带噪机器音数据作为微调数据,在领域增强预训练模型基础上进行有监督微调,区分不同机器的域和属性类型。模型微调完成后,从线性表征层获取用于异音检测的声纹表征。之后,使用K近邻方法,得到在训练集中与测试样本表征最相似的训练样本,并计算两者表征的欧式距离作为测试样本的异常分数。
最终,联合团队基于上述方案打造的机器声纹无监督异常检测系统,在测试集上得分为61.6276%,夺得该任务冠军。
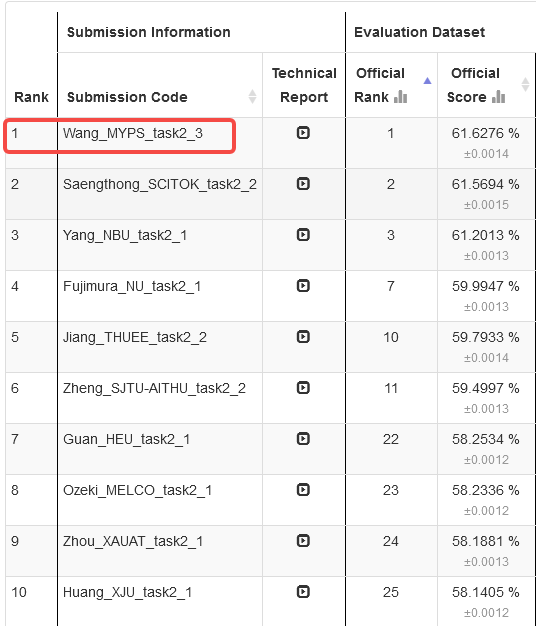
DCASE 2025 Task2榜单排名